前言
今天我们就来详细的聊聊 Redis 这四种特殊的数据类型之一 BitMap;
应用场景:二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
概述简介
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。

内部实现
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组 。
我们通过下面的命令来看下 BitMap 占用的空间大小:
# 首先将偏移量是0的位置设为1
# SETBIT key offset value
127.0.0.1:6379> SETBIT sid10t 0 1
(integer) 0
# 通过 STRLEN 命令,我们可以看到字符串的长度是1
# STRLEN key
127.0.0.1:6379> # STRLEN sid10t
(integer) 1
# 将偏移量是1的位置设置为1
127.0.0.1:6379> SETBIT sid10t 1 1
(integer) 0
# 此时字符串的长度还是为1,因为一个字符串有8个比特位,不需要再开辟新的内存空间
127.0.0.1:6379> STRLEN sid10t
(integer) 1
# 将偏移量是8的位置设置成1
127.0.0.1:6379> setbit sid10t 8 1
(integer) 0
# 此时字符串的长度变成2,因为一个字节存不下9个比特位,需要再开辟一个字节的空间
127.0.0.1:6379> STRLEN sid10t
(integer) 2
通过上面的实验我们可以看出,BitMap 占用的空间,就是底层字符串占用的空间。假如 BitMap 偏移量的最大值是 OFFSET_MAX,那么它底层占用的空间就是:
(OFFSET_MAX/8)+1 = 占用字节数
因为字符串内存只能以字节分配,所以上面的单位是字节。
但是需要注意,Redis 中字符串的最大长度是 512M,所以 BitMap 的 offset 值也是有上限的,其最大值是:
8 * 1024 * 1024 * 512 = 2^32
由于 C语言中字符串的末尾都要存储一位分隔符,所以实际上 BitMap 的 offset 值上限是:
(8 * 1024 * 1024 * 512) -1 = 2^32 - 1
常用命令
Bitmap 基本操作:
# 设置值,其中 value 只能是 0 和 1
# SETBIT key offset value
127.0.0.1:6379> SETBIT sid10t 0 1
(integer) 0
# 获取值
# GETBIT key offset
127.0.0.1:6379> GETBIT sid10t 1
(integer) 1
# 获取指定范围内值为 1 的个数
# start 和 end 以字节为单位
# BITCOUNT key [start end [BYTE|BIT]]
127.0.0.1:6379> BITCOUNT sid10t 0 8
(integer) 3
Bitmap 运算操作:
# BitMap 间的运算
# operations 位移操作符,枚举值
AND 与运算 &
OR 或运算 |
XOR 异或 ^
NOT 取反 ~
# result 计算的结果,会存储在该 key 中
# key1 … keyn 参与运算的 key,可以有多个,空格分割,not 运算只能一个 key
# 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节 byte 为单位),和输入 key 中最长的字符串长度相等。
BITOP [operations] [result] [key1] [keyn…]
# 返回指定 key 中第一次出现指定 value(0/1) 的位置
BITPOS [key] [value]
应用场景
Bitmap 类型非常适合二值状态统计的场景,这里的二值状态就是指集合元素的取值就只有 0 和 1 两种,在记录海量数据时,Bitmap 能够有效地节省内存空间。
签到统计
在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
假设我们要统计 ID 100 的用户在 2020 年 7 月份的签到情况,就可以按照下面的步骤进行操作。
第一步,执行下面的命令,记录该用户 7 月 23 号已签到。
127.0.0.1:6379> SETBIT sign 100:202007 22 1
100:202007 22 1
第二步,检查该用户 7 月 23 日是否签到。
127.0.0.1:6379> GETBIT sign100:202007 22 1
第三步,统计该用户在 7 月份的签到次数。
127.0.0.1:6379> BITCOUNT sign100:202007
这样,我们就知道该用户在 7 月份的签到情况了。
如何统计这个月首次打卡时间呢?
Redis 提供了 BITPOS key bitValue [start] [end] 指令,返回数据表示 Bitmap 中第一个值为 bitValue 的 offset 位置。
在默认情况下, 命令将检测整个位图, 用户可以通过可选的 start 参数和 end 参数指定要检测的范围。所以我们可以通过执行这条命令来获取 userID = 100 在 2020 年 7 月份首次打卡日期:
127.0.0.1:6379> BITPOS uid 100:202007 1
100:202007 1
需要注意的是,因为 offset 从 0 开始的,所以我们需要将返回的 value + 1 。
判断用户登陆态
Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT 判断对应的用户是否在线。 50000 万用户只需要 6 MB 的空间。
假如我们要判断 ID = 10086 的用户的登陆情况:
第一步,执行以下指令,表示用户已登录。
127.0.0.1:6379> SETBIT login_status 10086 1
第二步,检查该用户是否登陆,返回值 1 表示已登录。
127.0.0.1:6379> GETBIT login_status 10086
第三步,登出,将 offset 对应的 value 设置成 0。
127.0.0.1:6379> SETBIT login_status 10086 0
连续签到用户总数(项目一:Online学习平台的用户连续签到的功能)
如何统计出这连续 7 天连续打卡用户总数呢?
我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。
key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。
一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』 运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。
结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 7 天的用户总数了。
Redis 提供了 BITOP operation destkey key [key ...] 这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
operation 可以是 and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0 。空的 key 也被看作是包含 0 的字符串序列。
假设要统计 3 天连续打卡的用户数,则是将三个 Bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计,如下命令:
# 与操作
127.0.0.1:6379> BITOP AND destmap bitmap:01 bitmap:02 bitmap:03
# 统计 bit 位 = 1 的个数
127.0.0.1:6379> BITCOUNT destmap
即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(108/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
某一用户连续签到的天数
前面提到了对连续签到7天的用户总数的统计,是对多个BitMap运算的结果; 接下来需求来了?我该如何统计某一用户连续签到的天数
- 获取本月到今天为止的所有签到数据
- 从今天开始,向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数
如图:

如果用一个伪代码来表示,大概是这样:
int count = 0; // 定义一个计数器
for(/*从后向前遍历签到记录中的每一个bit位*/){
// 判断是否是1
// 如果是,则count++
}
这里存在几个问题:
- 如何才能得到本月到今天为止的所有签到记录?
- 如何从后向前遍历每一个bit位?
至于签到记录,可以利用我们之前讲的BITFIELD命令来获取,从0开始,到今天为止的记录,命令是这样的:
BITFIELD key GET u[dayOfMonth] 0
但是遍历bit位该怎么操作?我们从没学过二进制数字的遍历啊!
你可以把二进制数中的每一个bit位当做弹夹中的一个个的子弹。遍历bit位的过程,就是打空弹夹的过程:
- 将弹夹最上方的子弹上膛(找到最后一个bit位,并获取它)
- 发射子弹(移除这个bit位,下一个bit位就成为最后一个)
- 回到步骤1 最终,每一发子弹都会从备发射,这就像每一个bit位都会被遍历。
因此,现在问题就转化为两件事情:
- 如何找到并获取签到记录中最后一个bit位
- 任何数与1做与运算,得到的结果就是它本身。因此我们让签到记录与1做与运算,就得到了最后一个bit位
- 如何移除这个bit位
- 把数字右移一位,最后一位到了小数点右侧,由于我们保留整数,最后一位自然就被丢弃了
private int countSignDays(String key, int len) {
// 1.获取本月从第一天开始,到今天为止的所有签到记录
List<Long> result = redisTemplate.opsForValue()
.bitField(key, BitFieldSubCommands.create().get(
BitFieldSubCommands.BitFieldType.unsigned(len)).valueAt(0));
if (CollUtils.isEmpty(result)) {
return 0;
}
int num = result.get(0).intValue();
// 2.定义一个计数器
int count = 0;
// 3.循环,与1做与运算,得到最后一个bit,判断是否为0,为0则终止,为1则继续
while ((num & 1) == 1) {
// 4.计数器+1
count++;
// 5.把数字右移一位,最后一位被舍弃,倒数第二位成了最后一位
num >>>= 1;
}
return count;
}
哈哈哈,其实这主要是对bit位进行的位运算,和BitMap指令BITFIELD key GET u[dayOfMonth] 0
对40亿的QQ号去重
首先我们来看看如果要存储40亿QQ号需要多少内存?我们使用无符号整数存储,一个整数需要4个字节,那么40亿需要4*4000000000/1024/1024/1024≈15G,在业务中我们往往需要更多的空间。而且在Java中并不存在无符号整形,只有几个操作无符号的静态方法。
1GB = 1024MB,1MB = 1024KB,1KB = 1024B, 1B = 8b
很显然这种存储是不太优雅的,对于这种大数据量的去重,我们可以使用位图Bitmap。

假如我们要判断2924357571是否存在,那么我们只需要看index为2924357571的值是否为1,如果为1则表示已经存在。
位图使用1个比特表示一个数是否存在,那么使用无符号整数表示QQ号,4字节2^32-1是4294967295,内存需要4294967295/8/1024/1024≈512MB。 使用Java编程时,我们使用位图一般是通过的redis,在redis中位图常用的是以下三个命令:
| 命令 | 功能 |
|---|---|
| SETBIT key offset value | 设置指定offset位置的值,value只能是0或1 |
| GETBIT key offset | 获取指定offset位置的值 |
| BITCOUNT key start end | 获取start到end之间value为1的数量 |
还适用于如下场景
- 大数据量去重,Bitmap其极致的空间用在大数据量去重非常合适的,除了QQ号去重,我们还可以用在比如订单号去重;爬取网站时URL去重,爬过的就不爬取了。
- 数据统计,比如在线人员统计,将在线人员id为偏移值,为1表示在线;视频统计,将全部视频的id为偏移存储到Bitmap中。
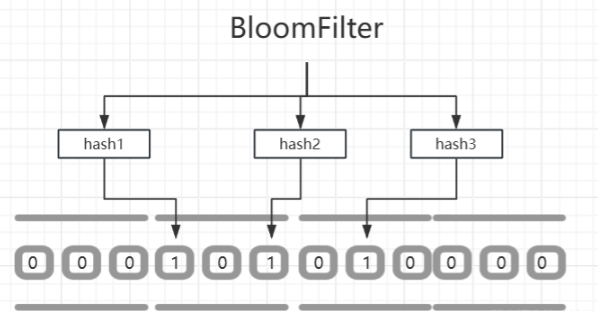
- 布隆过滤器(BloomFilter),布隆过滤器的基础就是使用的位图,只不过布隆过滤器使用了多个哈希函数处理,只有当全部的哈希都为1,才表示这个值存在。
hutool工具中布隆过滤器的实现类BitMapBloomFilter默认就提供了5个哈希函数
public BitMapBloomFilter(int m) {
int mNum =NumberUtil.div(String.valueOf(m), String.valueOf(5)).intValue();
long size = mNum * 1024 * 1024 * 8;
filters = new BloomFilter[]{
new DefaultFilter(size),
new ELFFilter(size),
new JSFilter(size),
new PJWFilter(size),
new SDBMFilter(size)
};
}
优点:相较位图,布隆过滤器使用多个hash算法,我们就可以给字符串或对象存进去计算hash了,不像位图一样只能使用整形数字看偏移位置是否为1。
缺点:可能产生哈希冲突,如果判断某个位置值为1,那么可能是产生了哈希冲突,所以,布隆过滤器会有一定误差。






评论( 0 )