前言
哈哈哈,虽然这里是多级缓存的标题实际上这个里面只引入了本地缓存Caffinie。因为我觉得有以下两个原因
-
课程分类引入一级缓存已经足够应对项目需求(毕竟这个分类数据不怎么变化,真变了大不了再去查数据库呗,这也是非常低频的)
-
引入多级缓存的话,我们还要保证多级缓存之间的缓存一致性,数据库一致性,等等这都反而得不偿失,增加了维护的成本
这个项目中的多级缓存场景我觉得不如我的项目二更加的适合物流项目中的多级缓存:准达物流的多级缓存
背景
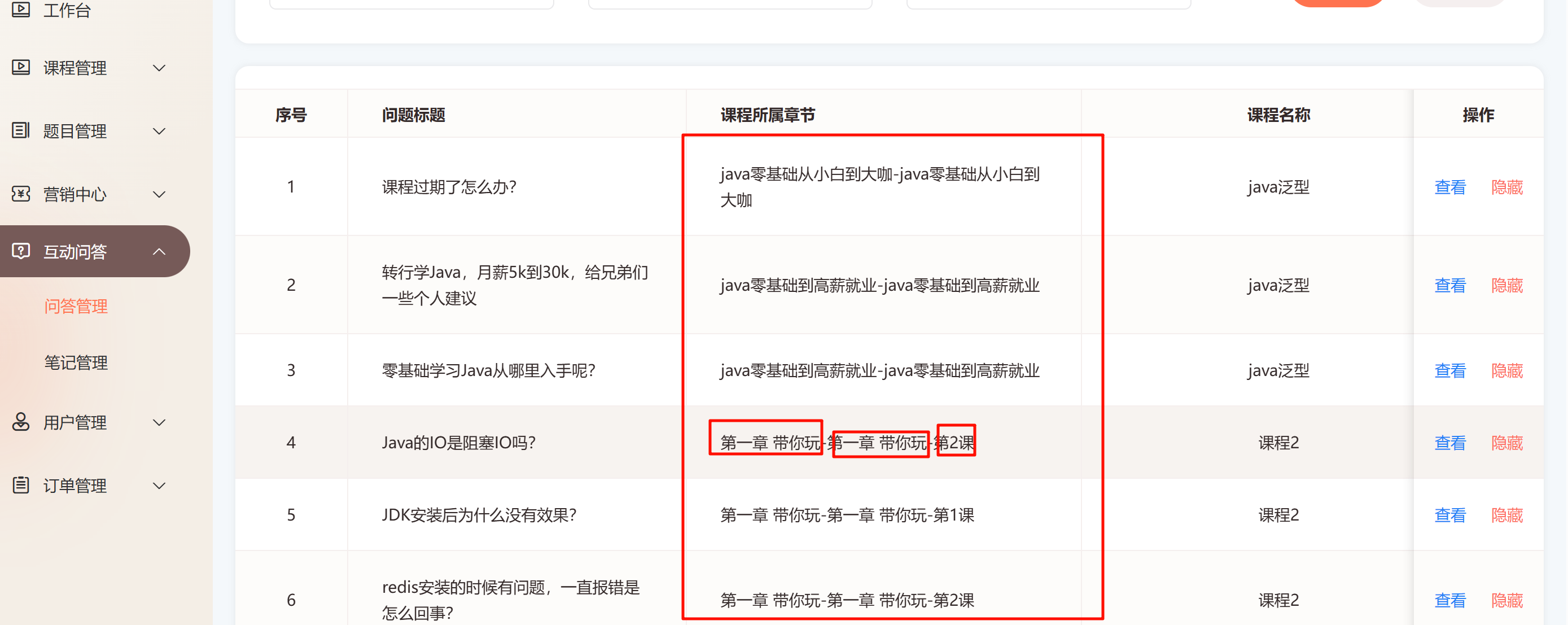
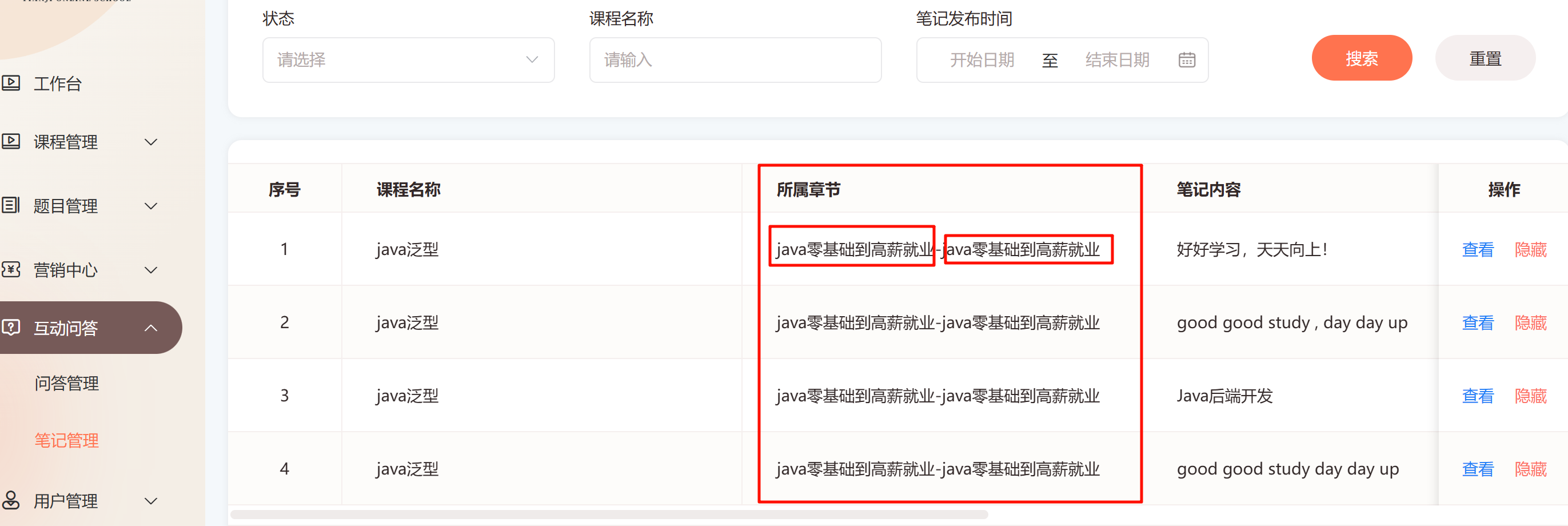
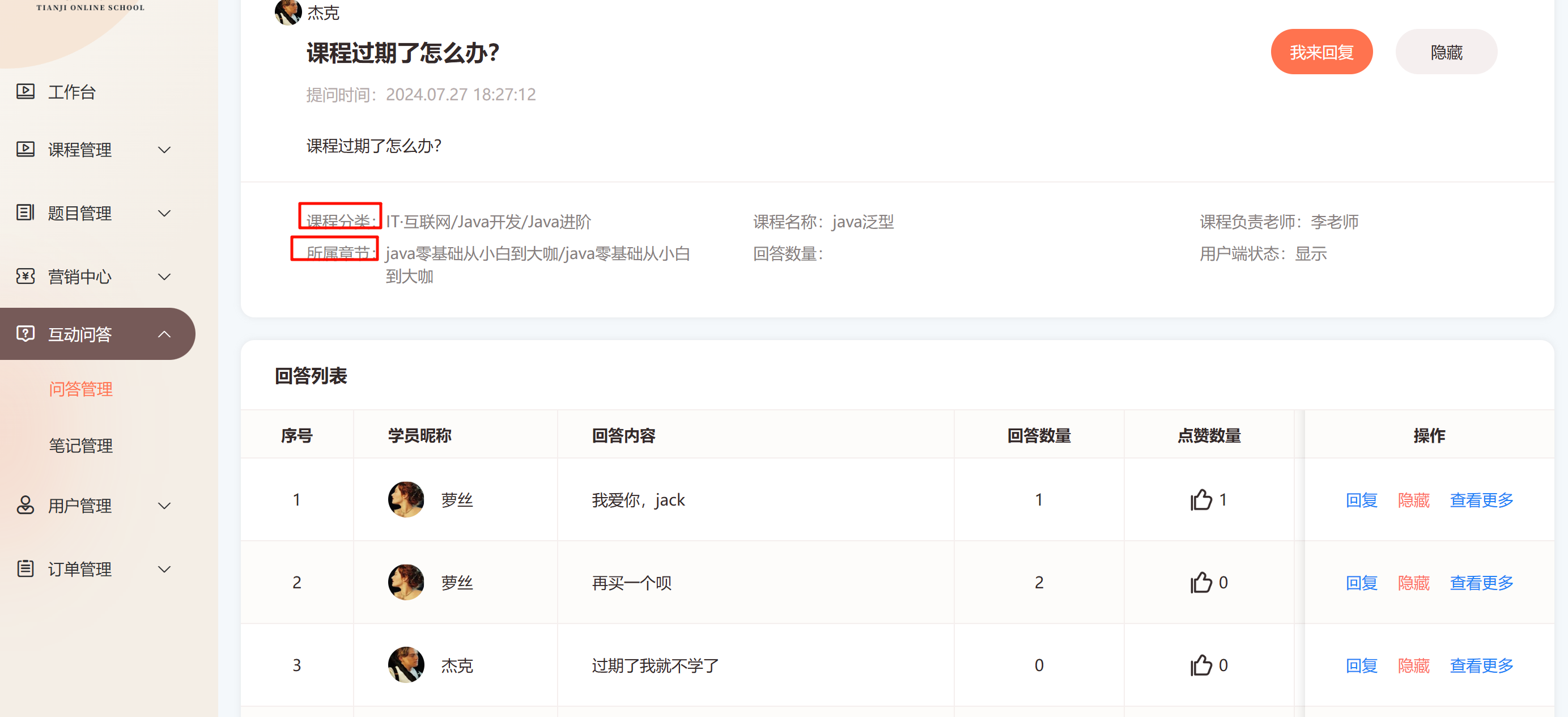
如图
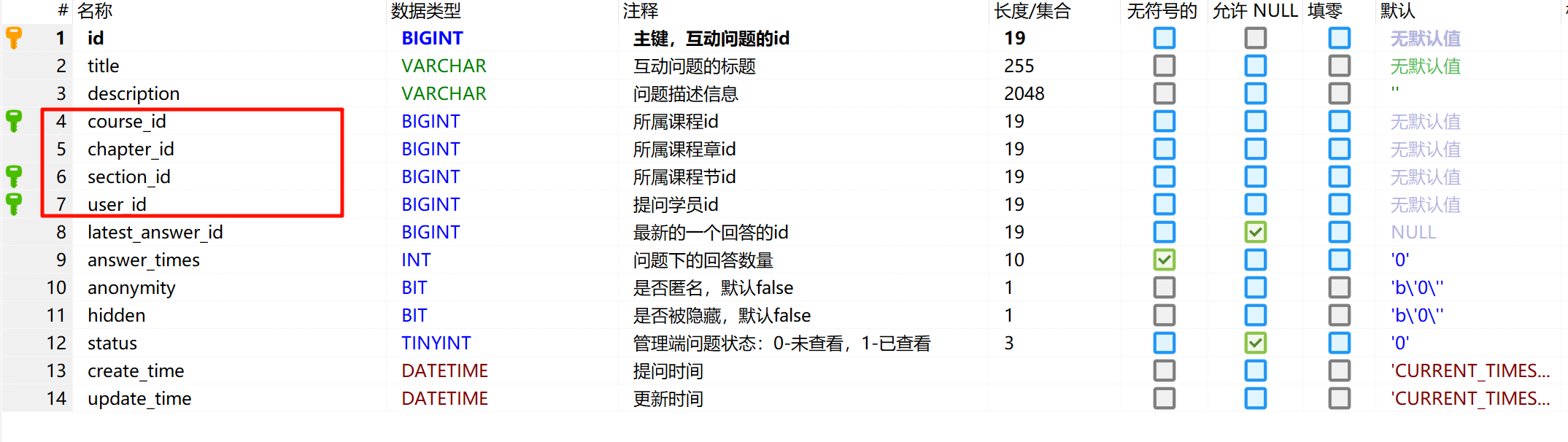
在我的Online学习平台项目中,当管理员端查看学员在学习过程中产生的问答和笔记的查询情况如上
管理端除了要查询到问题,还需要返回问题所属的一系列信息:
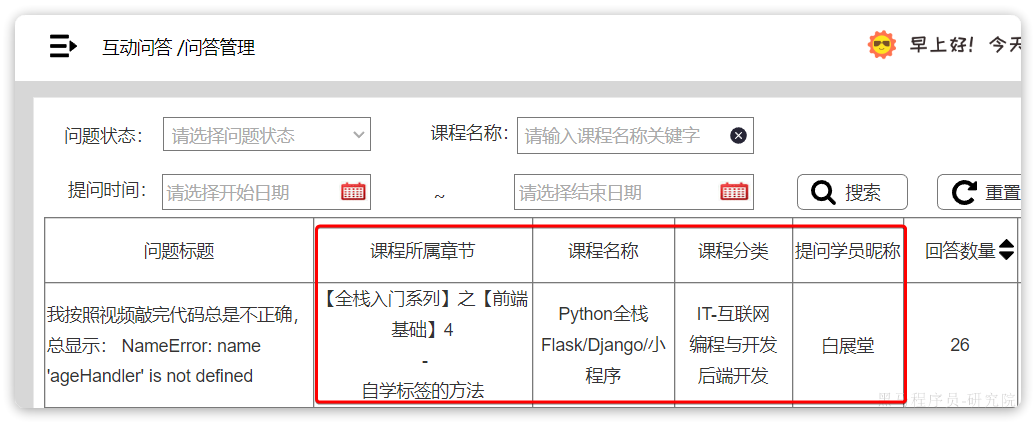
这些数据对应到interaction_question表中,只包含一些id字段:
思路
那么我们该如何获取其名称数据呢?
- 课程名称:根据
course_id到 课程微服务 查询 - 章节名称:根据
chapter_id和section_id到课程微服务查询 - 分类:未知
- 提问者名称:根据
user_id到 用户微服务 查询 其中,课程、章节、提问者等信息的查询在以往的业务中我们已经涉及到,不再赘述。但是课程分类信息以前没有查询过。
课程数据为了提升搜索速度我们是放到ElasticSearch中的,可以根据课程名称来搜索其课程的目录Id集合
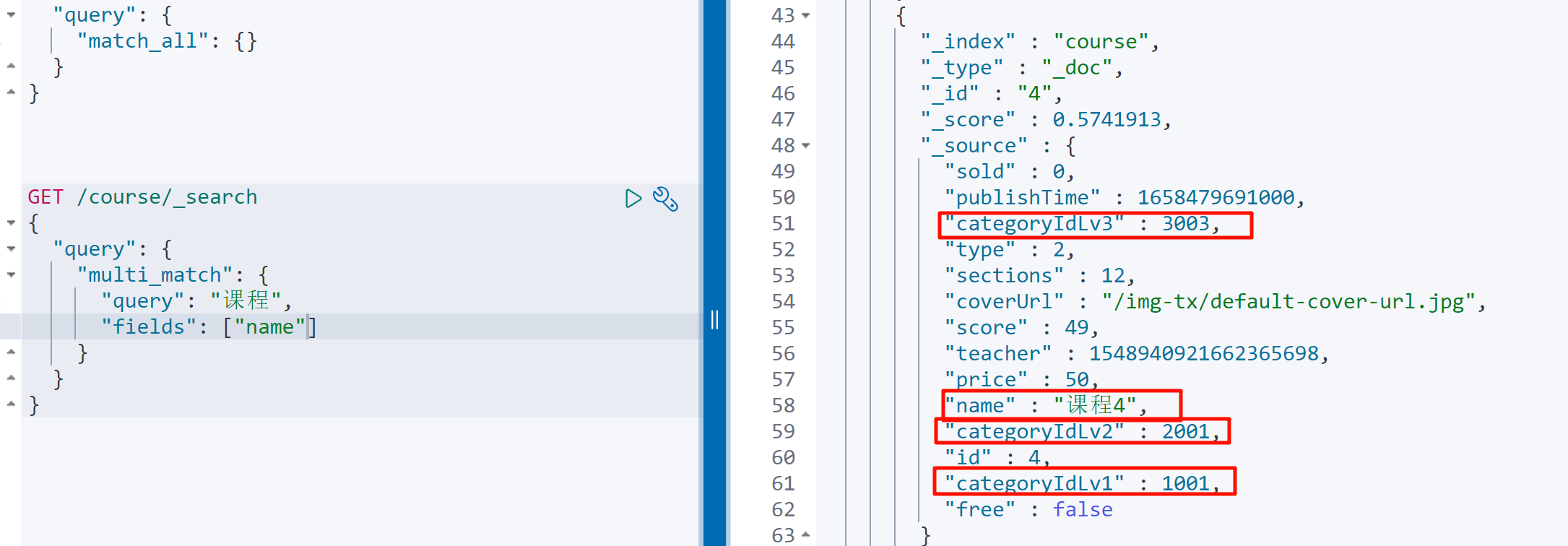
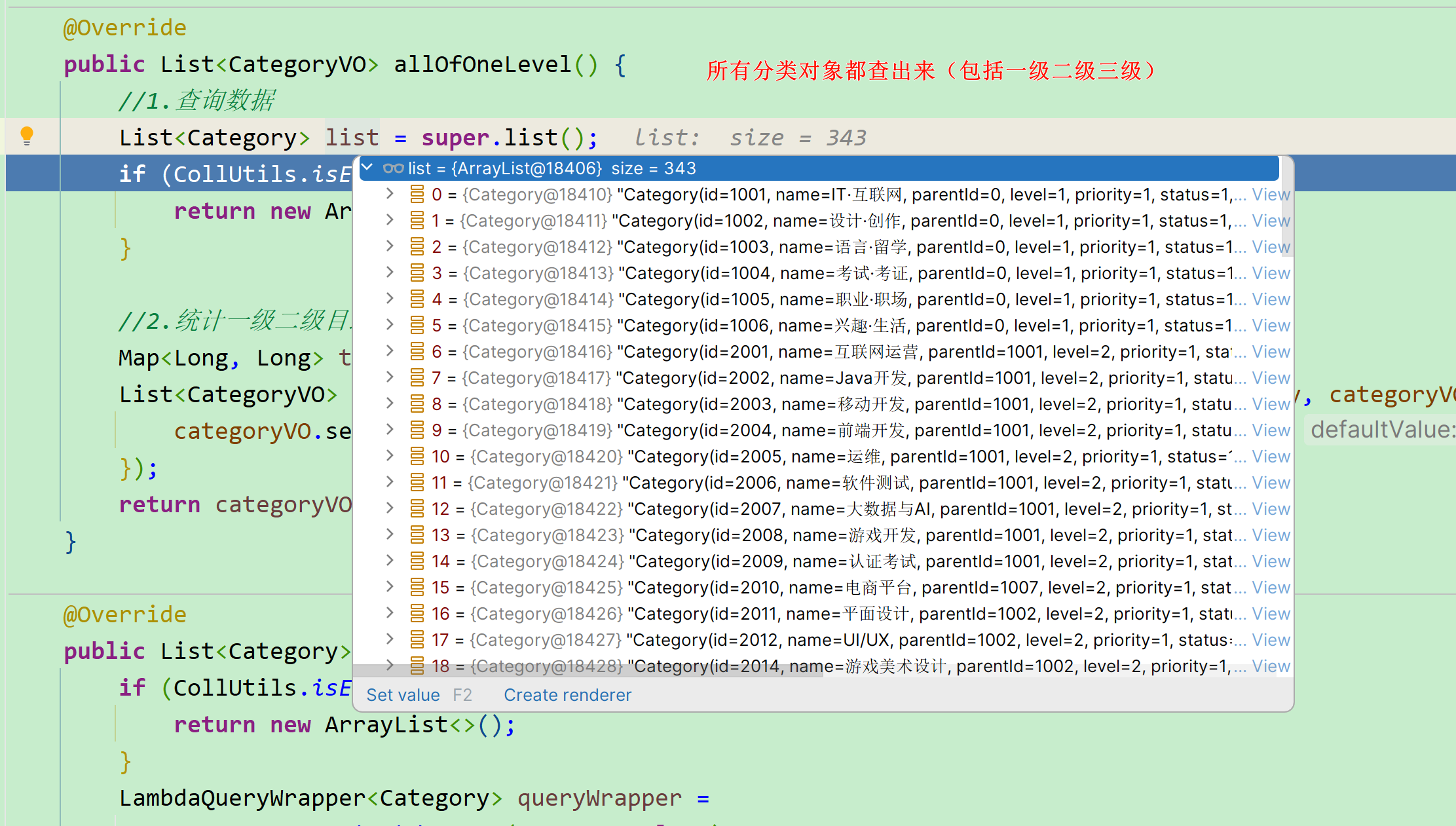
课程分类在首页就能看到,共分为3级:
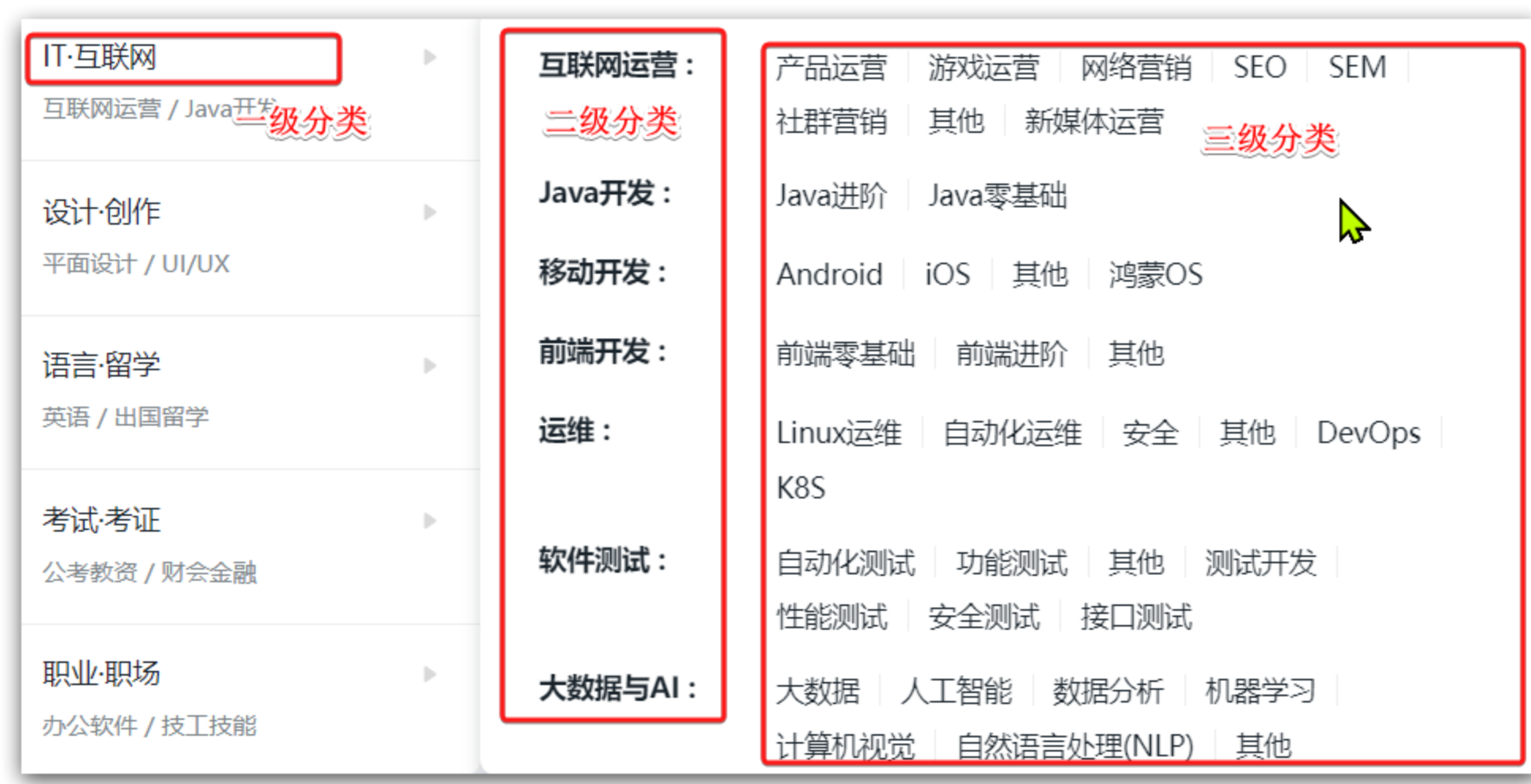
每一个课程都与 第三级分类 关联,因此向上级追溯,也有对应的二级、一级分类。在课程微服务提供的查询课程的接口中,可以看到返回的课程信息中就包含了关联的一级、二级、三级分类:
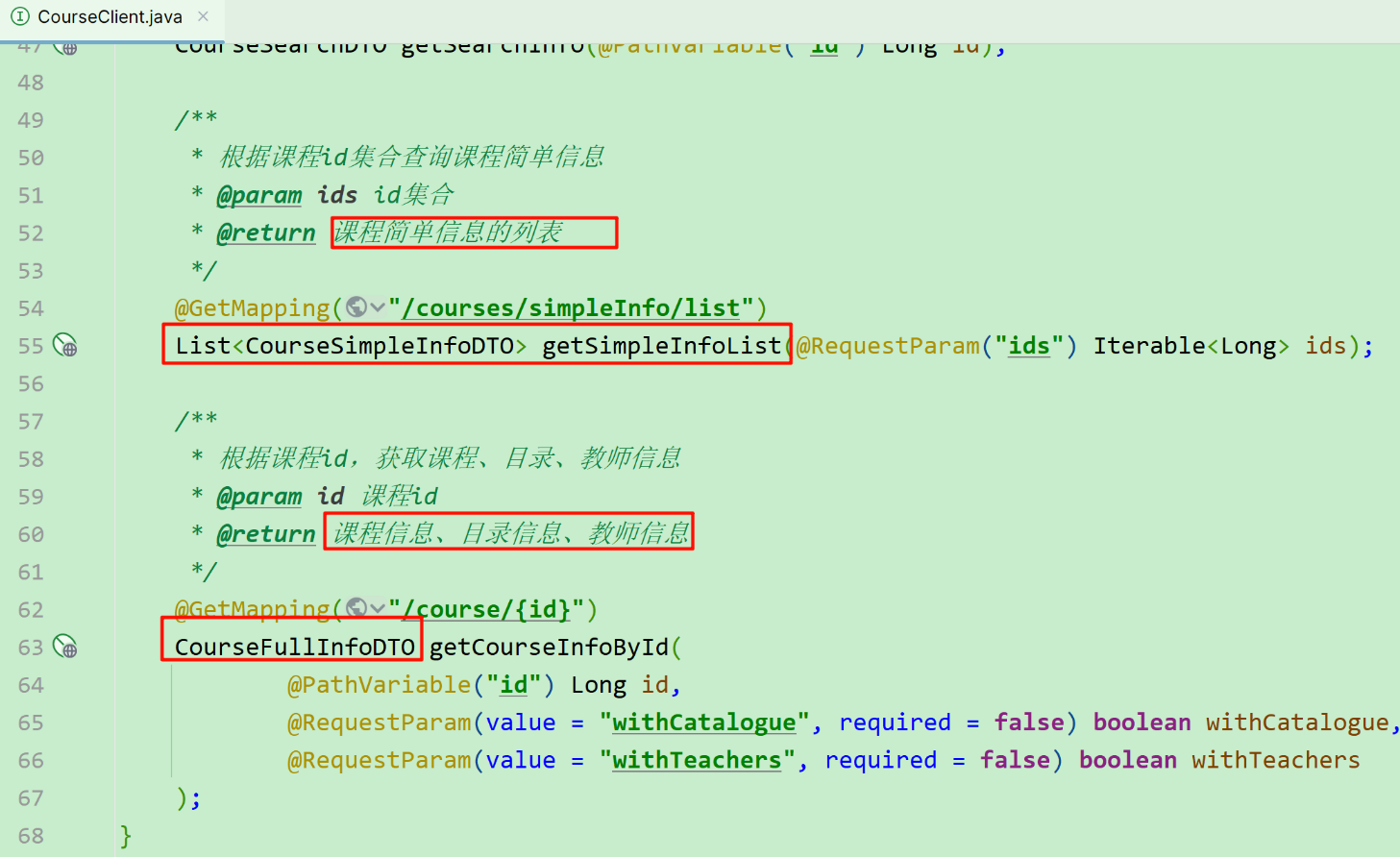
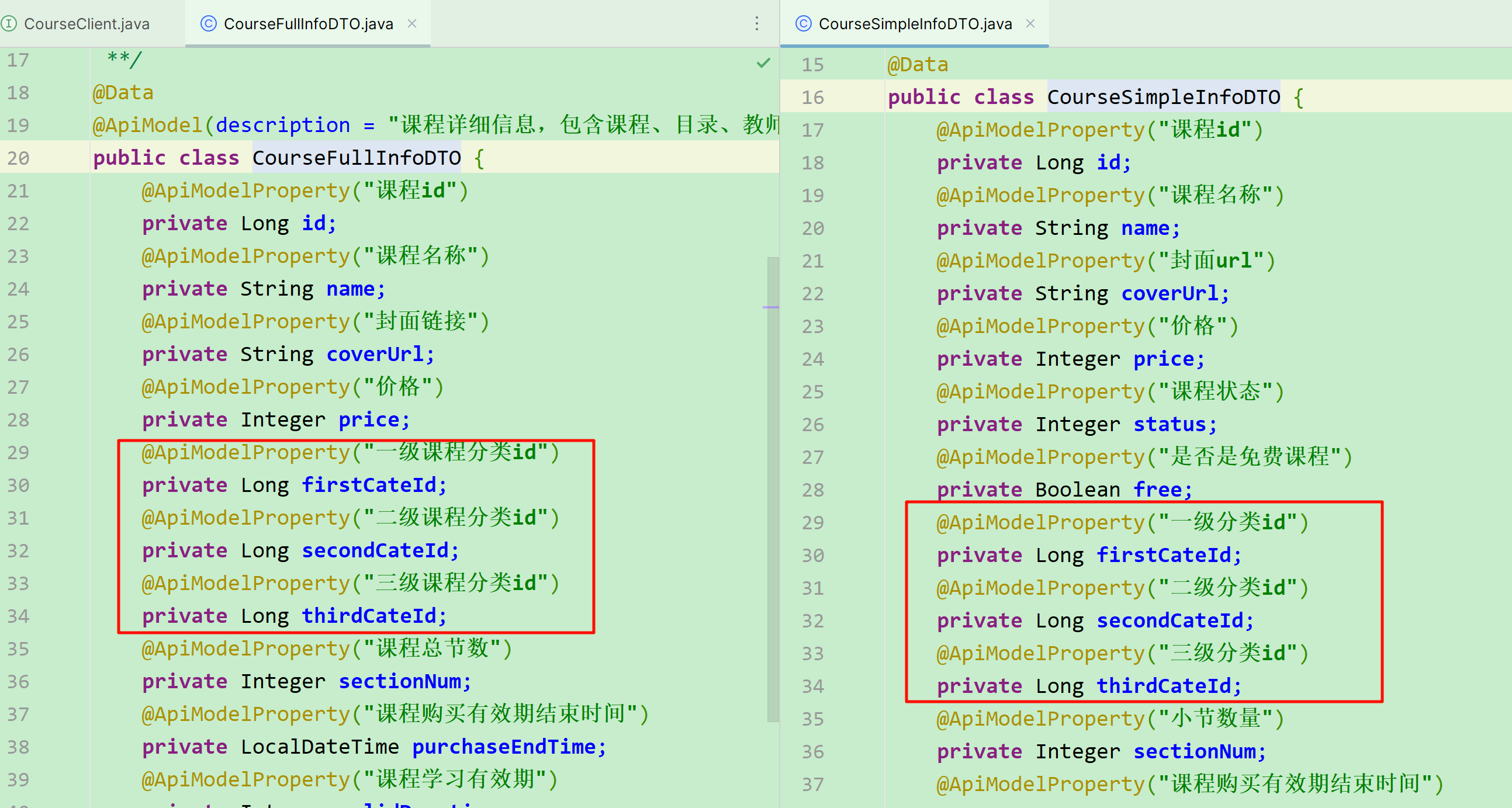
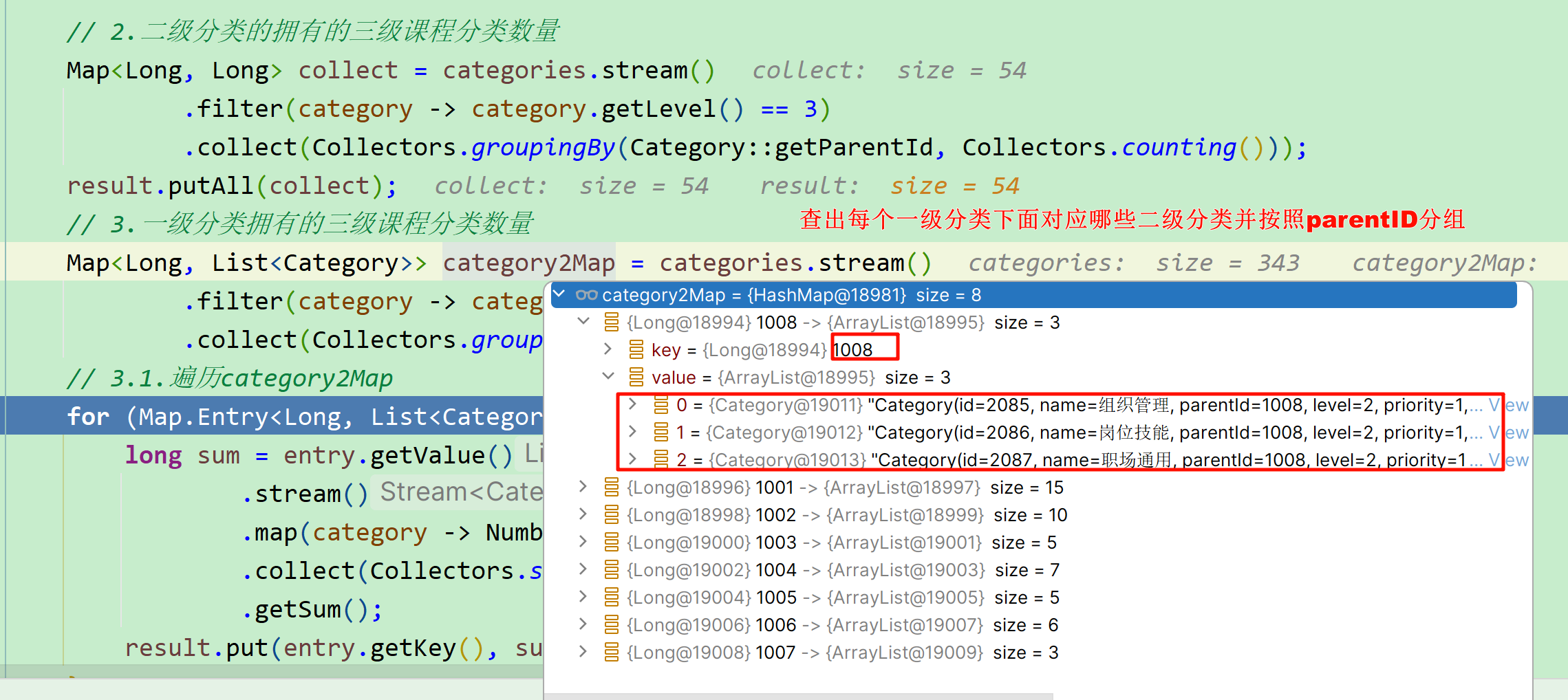
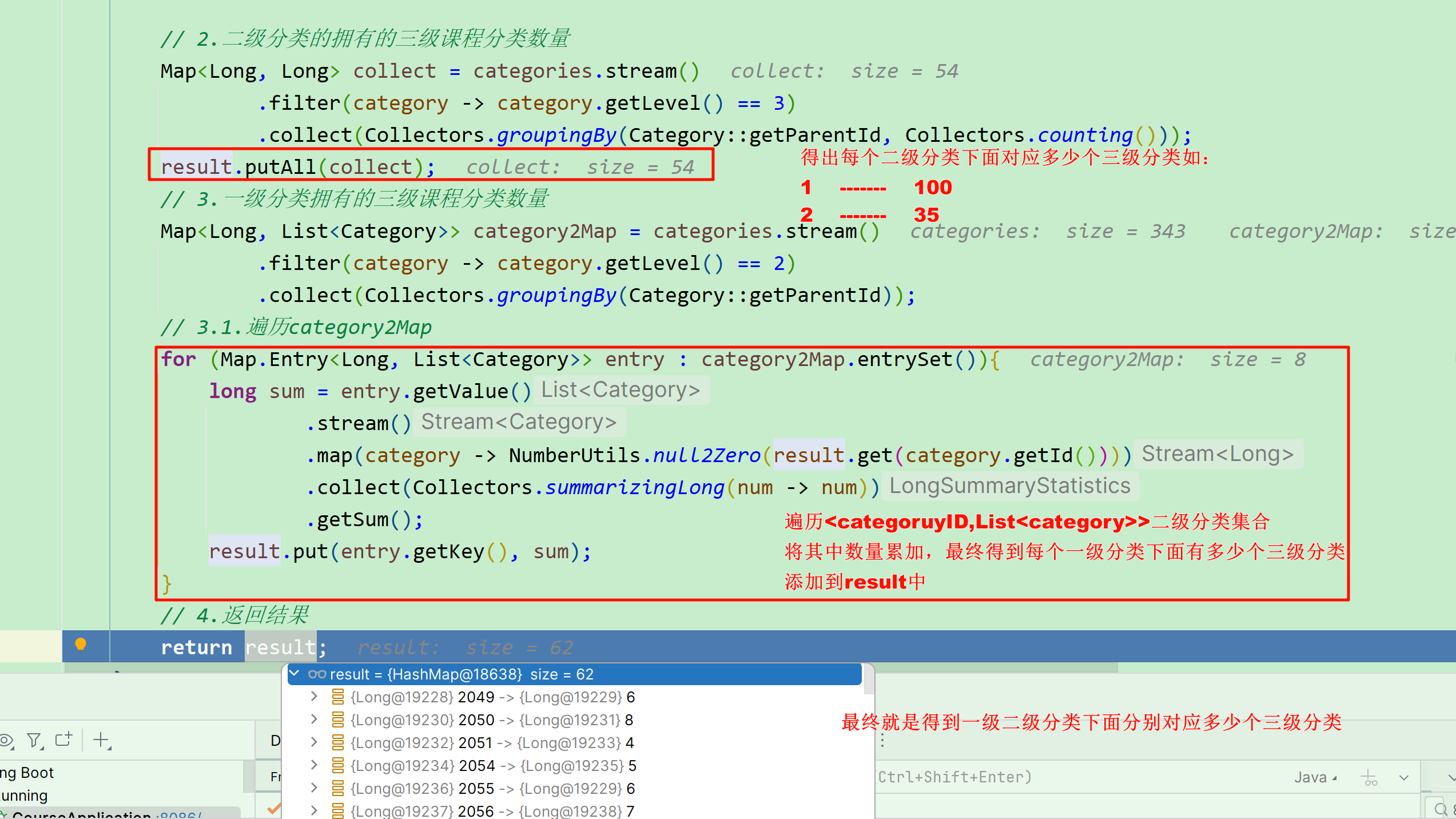
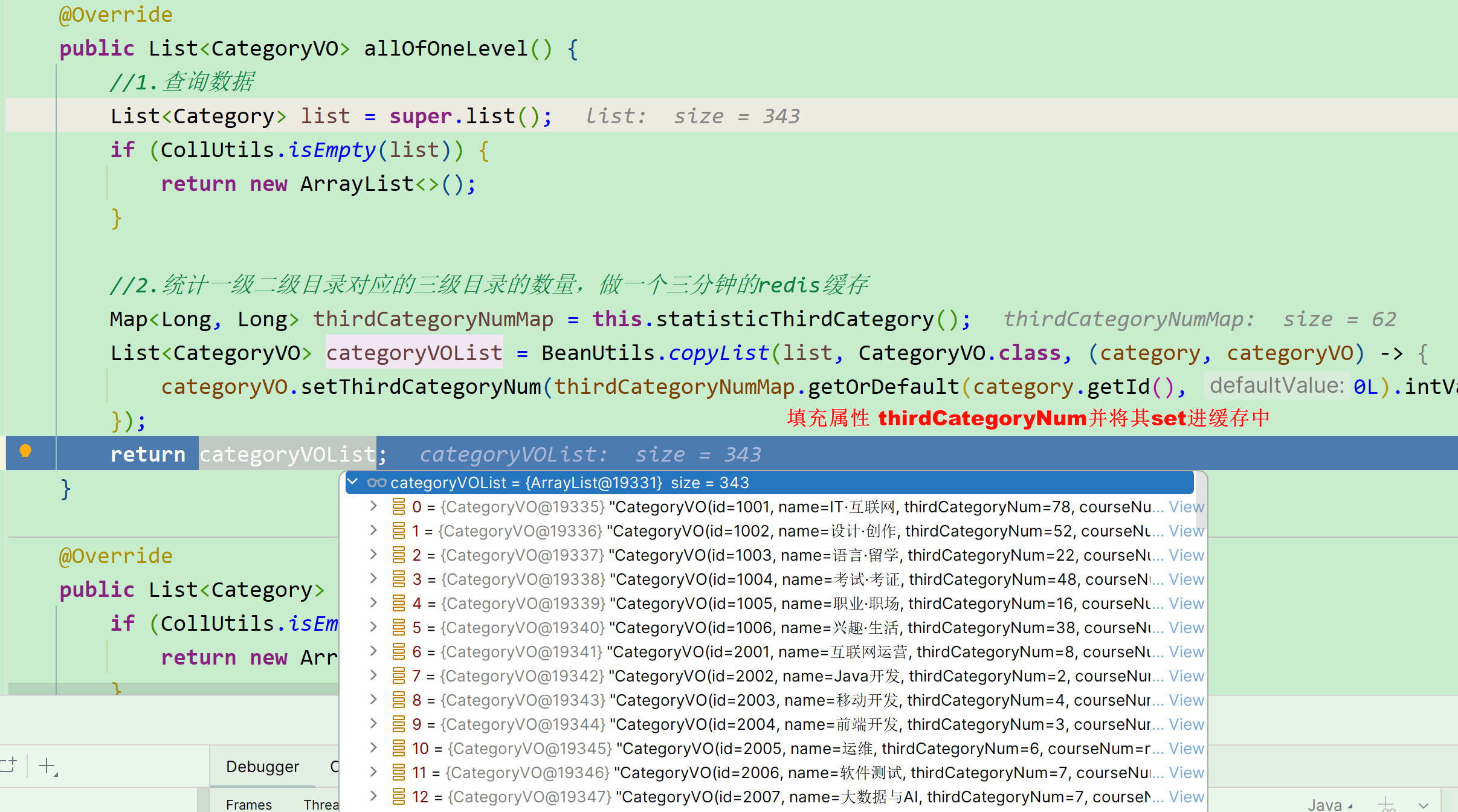
因此,只要我们查询到了 问题所属的课程,就能知道课程关联的三级分类id ,接下来只需要根据分类id查询出分类名称即可。
而在course-service服务中提供了一个接口,可以查询到所有的分类:
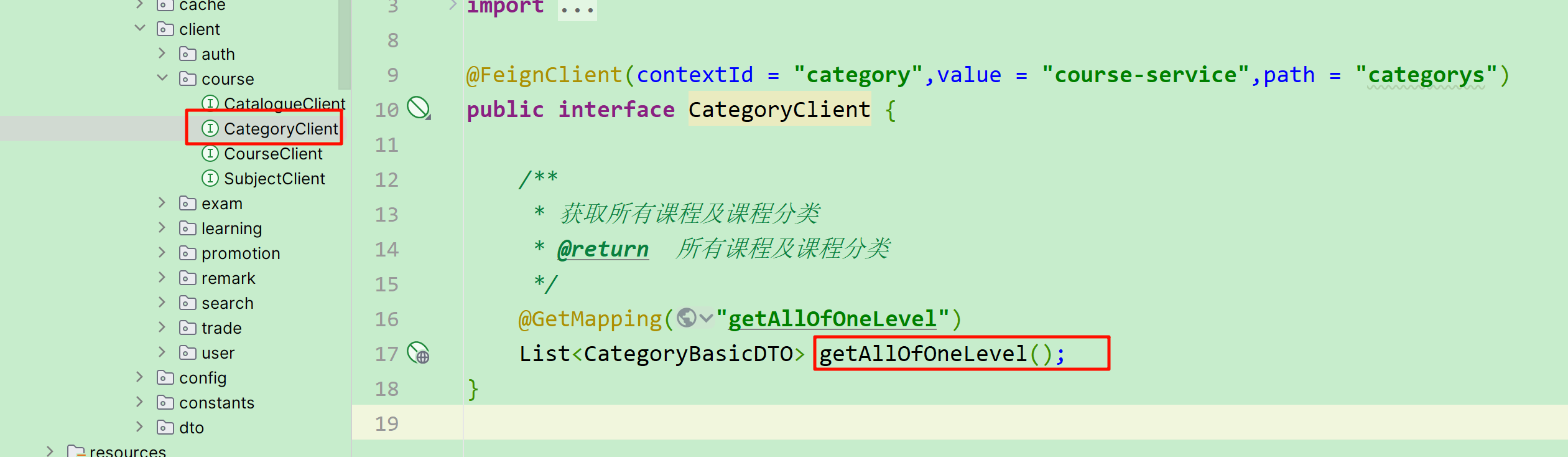
需要注意的是:这个返回的是所有课程分类的集合,而课程中只包含3个分类id。因此我们需要自己 从所有分类集合中找出课程有关的这三个 。 分析到这里大家应该知道如何做了。不过这里有一个值得思考的点:
- 课程分类数据在很多业务中都需要查询,这样的数据如此频繁的查询,有没有性能优化的办法呢?
方案
多级缓存
而分类数据具备两大特点:
- 数据量小
- 长时间不会发生变化。 像这样的数据,除了建立Redis缓存以外,还非常适合做 本地缓存(Local Cache) 。这样就可以形成多级缓存机制:
- 数据查询时 优先查询本地缓存
- 本地缓存不存在,再查询 Redis缓存
- Redis不存在,再去查询
数据库。
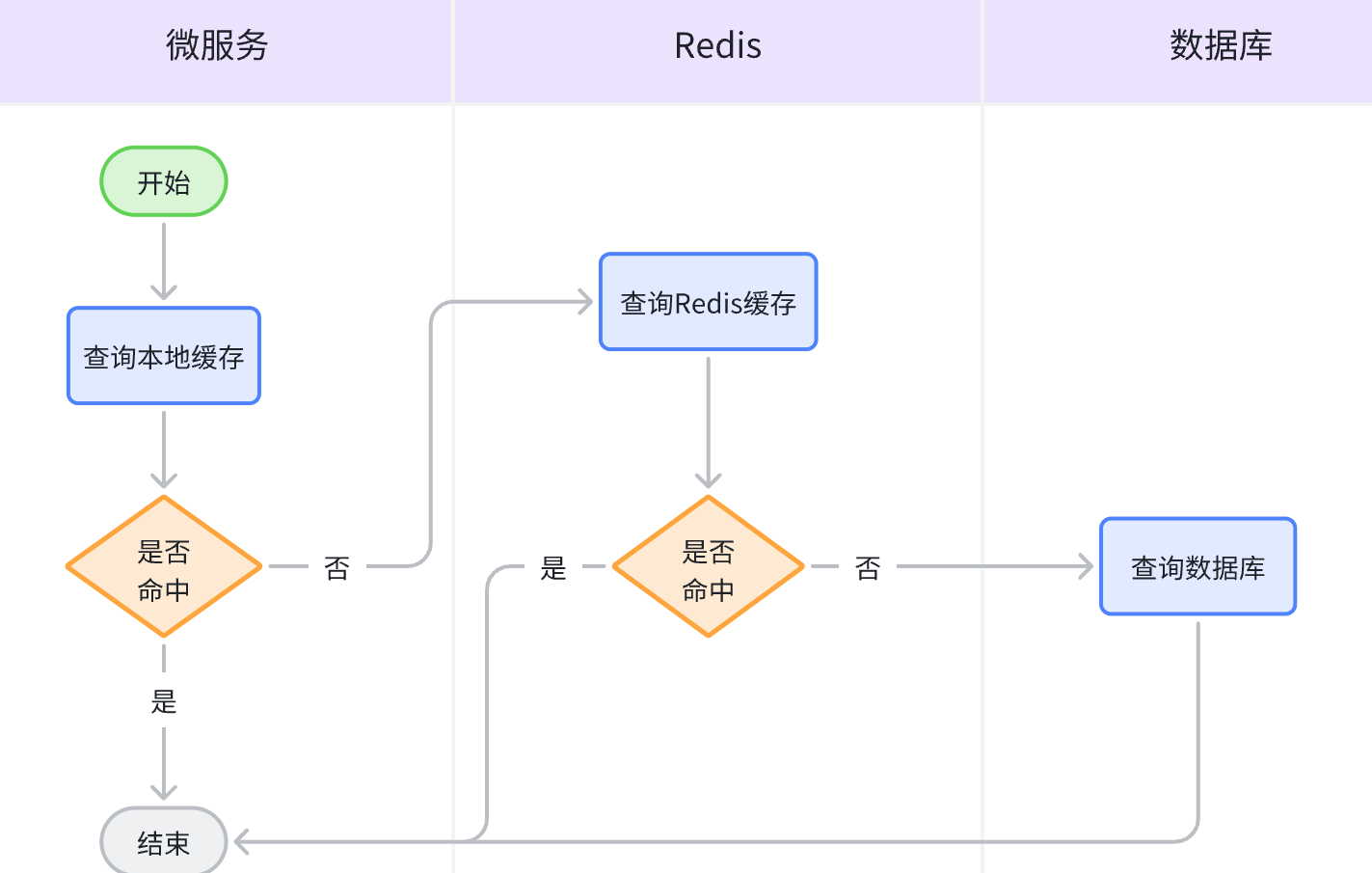
本地缓存简单来说就是 JVM内存的缓存,比如你建立一个HashMap,把数据库查询的数据存入进去。以后优先从这个HashMap查询,一个本地缓存就建立好了。 本地缓存优点:
- 读取本地内存,没有 网络开销,速度更快 本地缓存缺点:
- 数据
同步困难,一般采用自动过期方案 - 存储容量有限、可靠性较低、无法共享
本地缓存由于无需网络查询,速度非常快。不过由于上述缺点,本地缓存往往适 用于数据量小、更新不频繁的数据。而课程分类恰好符合 。
我们这里采用的是Caffeine
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();
- 基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();
- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
CategoryCacheConfig(Caffeine的配置类)
public class CategoryCacheConfig {
/**
* 课程分类的caffeine缓存
*/
@Bean
public Cache<String, Map<Long, CategoryBasicDTO>> categoryCaches(){
return Caffeine.newBuilder()
.initialCapacity(1) // 容量限制
.maximumSize(10_000) // 最大内存限制
.expireAfterWrite(Duration.ofMinutes(30)) // 有效期
.build();
}
/**
* 课程分类的缓存工具类
*/
@Bean
public CategoryCache categoryCache(
Cache<String, Map<Long, CategoryBasicDTO>> categoryCaches, CategoryClient categoryClient){
return new CategoryCache(categoryCaches, categoryClient);
}
}
而CategoryCache则是缓存使用的工具类。由于商品分类经常需要根据id查询,因此我根据id查询分类的各种API
@RequiredArgsConstructor
public class CategoryCache {
private final Cache<String, Map<Long, CategoryBasicDTO>> categoryCaches;
private final CategoryClient categoryClient;
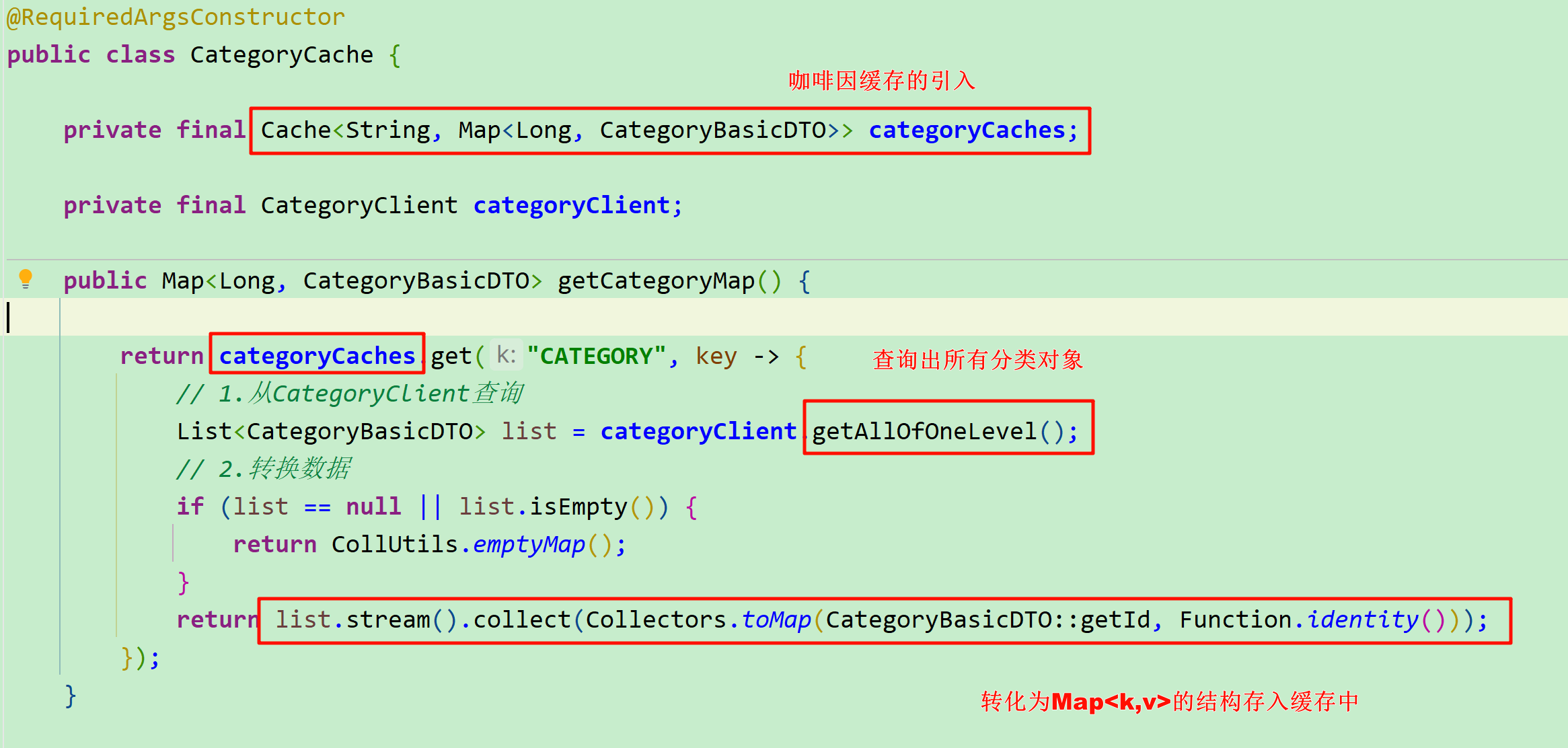
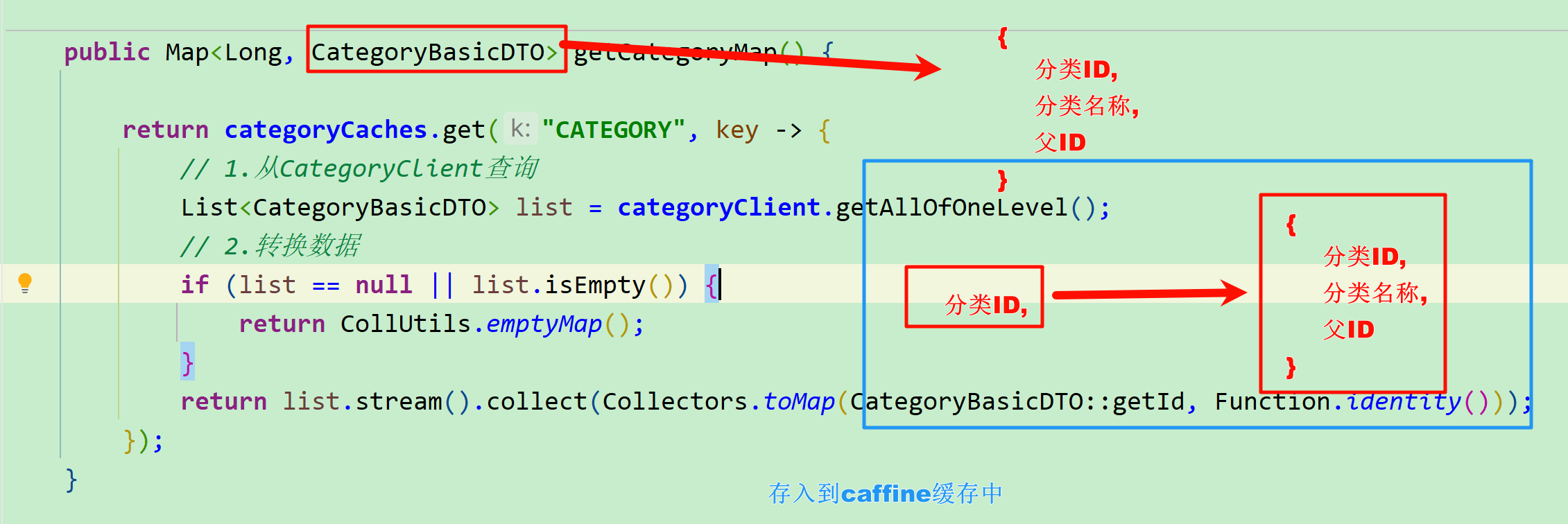
public Map<Long, CategoryBasicDTO> getCategoryMap() {
return categoryCaches.get("CATEGORY", key -> {
// 1.从CategoryClient查询
List<CategoryBasicDTO> list = categoryClient.getAllOfOneLevel();
// 2.转换数据
if (list == null || list.isEmpty()) {
return CollUtils.emptyMap();
}
return list.stream().collect(Collectors.toMap(CategoryBasicDTO::getId, Function.identity()));
});
}
public String getCategoryNames(List<Long> ids) {
if (ids == null || ids.size() == 0) {
return "";
}
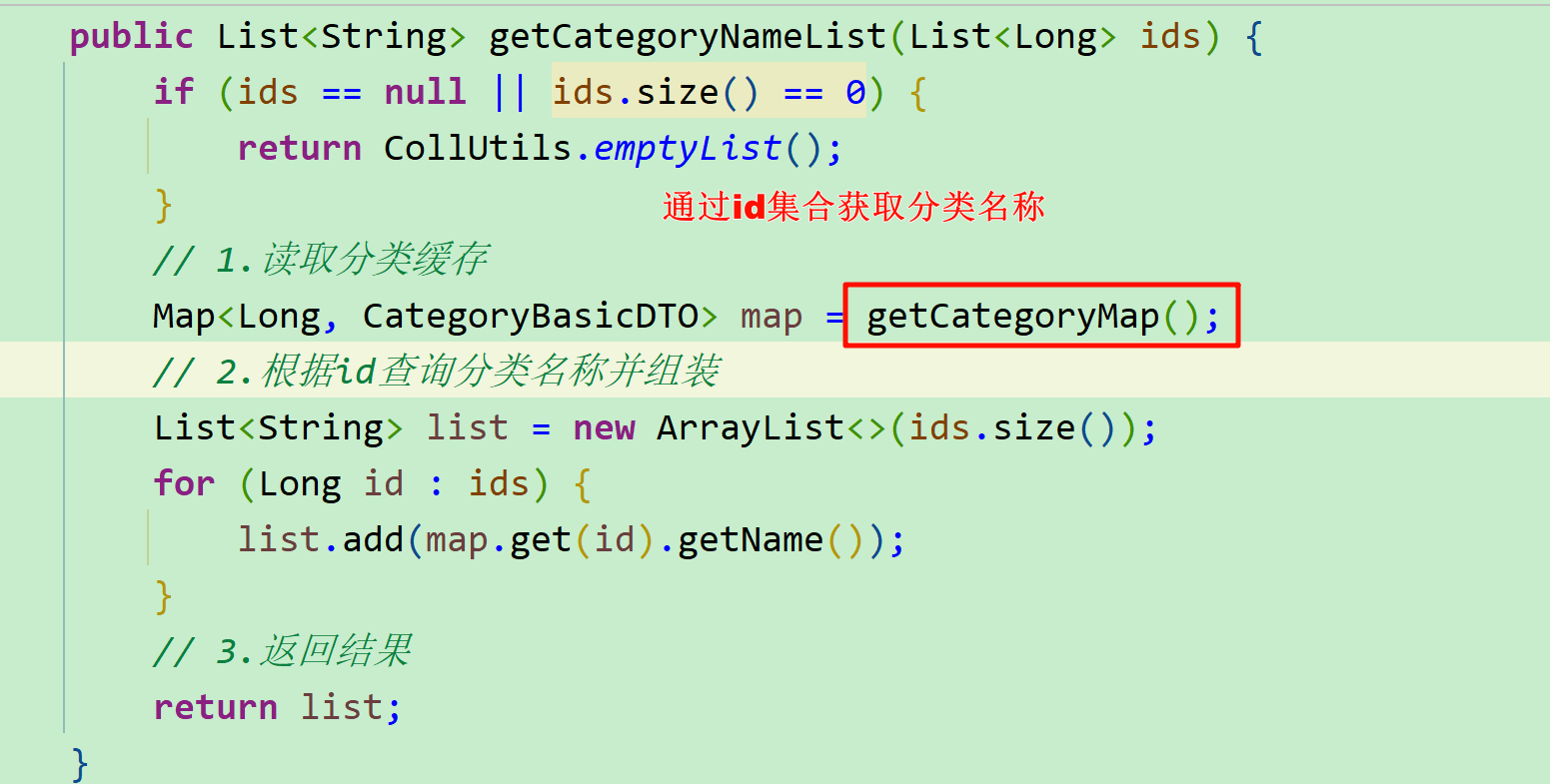
// 1.读取分类缓存
Map<Long, CategoryBasicDTO> map = getCategoryMap();
// 2.根据id查询分类名称并组装
StringBuilder sb = new StringBuilder();
for (Long id : ids) {
sb.append(map.get(id).getName()).append("/");
}
// 3.返回结果
return sb.deleteCharAt(sb.length() - 1).toString();
}
public List<String> getCategoryNameList(List<Long> ids) {
if (ids == null || ids.size() == 0) {
return CollUtils.emptyList();
}
// 1.读取分类缓存
Map<Long, CategoryBasicDTO> map = getCategoryMap();
// 2.根据id查询分类名称并组装
List<String> list = new ArrayList<>(ids.size());
for (Long id : ids) {
list.add(map.get(id).getName());
}
// 3.返回结果
return list;
}
public List<CategoryBasicDTO> queryCategoryByIds(List<Long> ids) {
if (ids == null || ids.size() == 0) {
return CollUtils.emptyList();
}
Map<Long, CategoryBasicDTO> map = getCategoryMap();
return ids.stream()
.map(map::get)
.collect(Collectors.toList());
}
public List<String> getNameByLv3Ids(List<Long> lv3Ids) {
Map<Long, CategoryBasicDTO> map = getCategoryMap();
List<String> list = new ArrayList<>(lv3Ids.size());
for (Long lv3Id : lv3Ids) {
CategoryBasicDTO lv3 = map.get(lv3Id);
CategoryBasicDTO lv2 = map.get(lv3.getParentId());
CategoryBasicDTO lv1 = map.get(lv2.getParentId());
list.add(lv1.getName() + "/" + lv2.getName() + "/" + lv3.getName());
}
return list;
}
public String getNameByLv3Id(Long lv3Id) {
Map<Long, CategoryBasicDTO> map = getCategoryMap();
CategoryBasicDTO lv3 = map.get(lv3Id);
CategoryBasicDTO lv2 = map.get(lv3.getParentId());
CategoryBasicDTO lv1 = map.get(lv2.getParentId());
return lv1.getName() + "/" + lv2.getName() + "/" + lv3.getName();
}
}
实现
以上是方案和对caffine缓存的一些配置和方法的提供,下面我们来看看代码中是怎么将课程中的分类数据查询出来放到缓存中的吧!
- 缓存的入口
- 整合分类信息






评论( 0 )