技能
技能一
熟练掌握Java基础,熟悉常用集合及底层数据结构、反射、类加载、多线程等
- 数组(Array):有序集合,可以包含重复的元素,常见实现类有ArrayList、Vector
- 链表(LinkedList):链表是一种动态数据结构,通过节点之间的链接来组织数据。常见的链表实现类是LinkedList
- 集合(Set):集合是不允许包含重复元素的无序集合。常见的集合实现类有HashSet、LinkedHashSet和TreeSet
- 映射(Map):映射是一种键值对的集合,每个键只能对应一个值。常见的映射实现类有HashMap、LinkedHashMap和TreeMap
- 队列(Queue):队列是一种先进先出(FIFO)的数据结构。常见的队列实现类有LinkedList和PriorityQueue
- 栈(Stack):栈是一种后进先出(LIFO)的数据结构。常见的栈实现类是Stack
- 树(Tree):树是一种具有分层结构的数据结构,常见的树实现类有BinaryTree和BinarySearchTree
反射 反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性
反射API
- Class 类:反射的核心类,可以获取类的属性,方法等信息。
- Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
- Method 类:Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
- Constructor 类:Java.lang.reflec 包中的类,表示类的构造方法。
类加载
加载 链接(验证、准备、解析) 初始化 使用 销毁
技能二
熟悉JVM内存结构、JMM、GC算法、常见的垃圾回收器CMS、G1工作原理 JMM
JVM内存结构
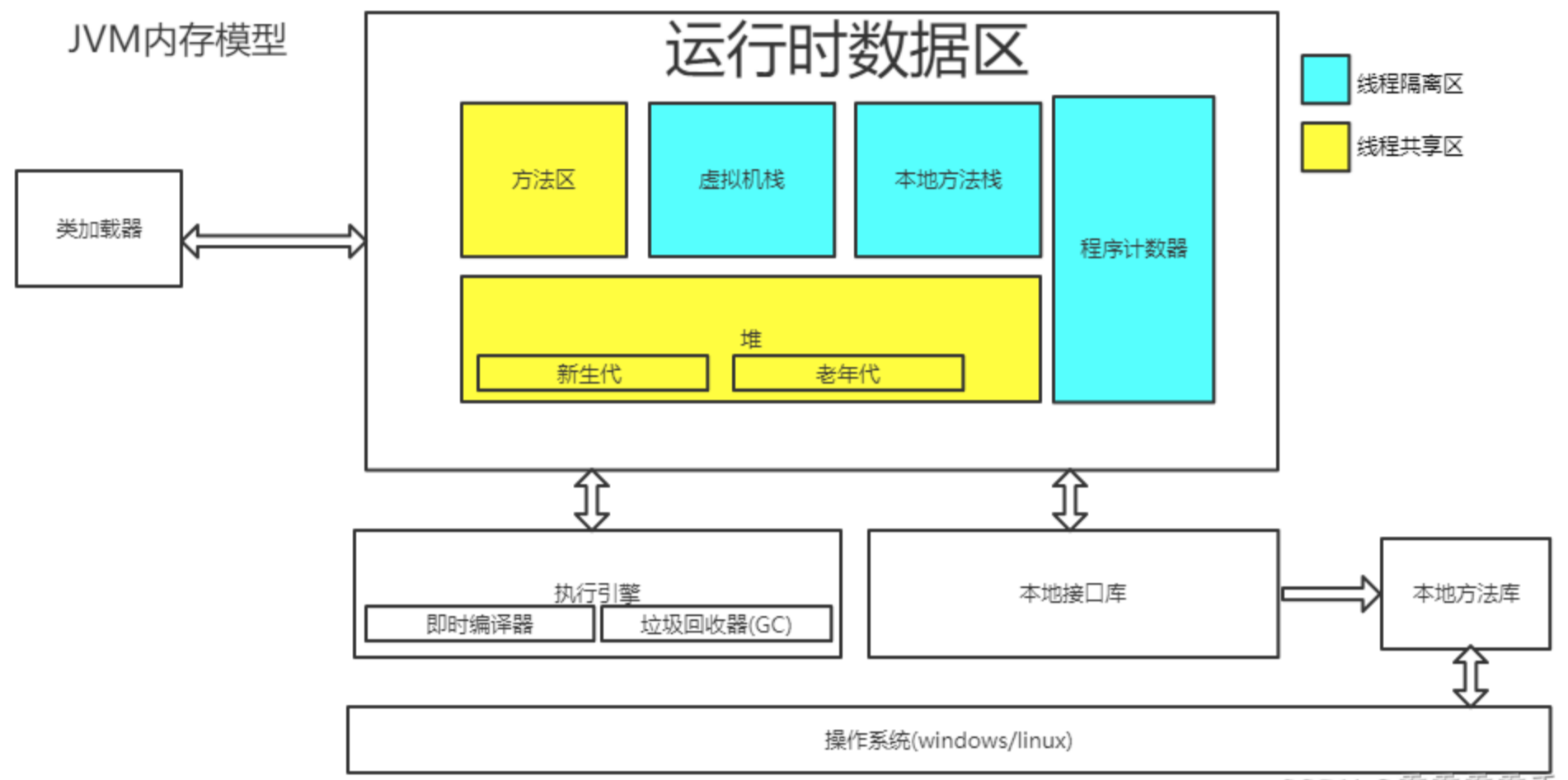
GC算法 复制(年轻代)
标记-清除(老年代)
标记-整理(老年代)
垃圾回收器
技能三
掌握 Java 并发编程,熟悉Java的锁机制、CAS、AQS、线程池、ThreadLocal、JUC中常用的工具类的实现与使用
Java的锁机制(synchronized 关键字和 Lock 接口及其实现类。)
- synchronized 关键字
- Lock 接口
- ReentrantLock
- ReentrantReadWriteLock
- 读锁跟写锁
- 读锁(Read Lock)
- 写锁(Write Lock)
CAS(比较并且交换,CPU同步原语)
CAS 包含了 3 个操作数:
- 需要读写的内存值 V
- 旧的预期值 A
- 要修改的更新值 B
当且仅当 V 的值等于 A 时,CAS 通过原子方式用新值 B 来更新 V 的 值,否则不会执行任何操作(他的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。)
缺点: ABA 问题,循环长时间开销,只能保证一个变量的原子操作
AQS
-
AQS 是一个锁框架,它定义了锁的实现机制,并开放出扩展的地方,让子类去实现,比如我们在lock 的时候,AQS 开放出 state 字段,让子类可以根据 state 字段来决定是否能够获得锁,对于获取不到锁的线程 AQS 会自动进行管理,无需子类锁关心,这就是 lock 时锁的内部机制,封装的很好,又暴露出子类锁需要扩展的地方;
-
AQS 底层是由同步队列 + 条件队列联手组成,同步队列管理着获取不到锁的线程的排队和释放,条件队列是在一定场景下,对同步队列的补充,比如获得锁的线程从空队列中拿数据,肯定是拿不到数据的,这时候条件队列就会管理该线程,使该线程阻塞;
-
AQS 围绕两个队列,提供了四大场景,分别是:获得锁、释放锁、条件队列的阻塞,条件队列的唤醒,分别对应着 AQS 架构图中的四种颜色的线的走向
ThreadLocal
JUC中常用的工具类(countdownlatch) countdownlatch
实习
技能一:设计模式
工厂+策略模式将不同的消息渠道和推送中台映射逻辑解耦,工厂+责任链模式对消息过滤和校验进行优化
策略模式有三种角色:选择器、抽象策略、策略实例
在我们消息下发过程中这个选择器最终是结合简单工厂来实现的,抽象策略我们定义了一个抽象类主要包含:下发渠道code、限流相关的参数、限流工厂、两个通用的方法:【(统一处理的handler接口,撤回消息的recall()方法),这两个方法其实是接口中的只不过是抽象类实现了该接口】,抽象策略中还有一个@PostConstruct修饰的init()方法,用于在子类初始化的时候将对应的handler放到工厂中(code作为key,handler作为value,放到一个EnumsMap中);然后具体的策略示例就继承这个抽象类:主要有什么阿里云、钉钉、企业微信、飞书、通知栏等等,这里面的策略示例就根据自己的业务需要对那两个方法重写,当然也包括自己的处理方法;需要注意的是这些 策略示例都会有一个构造方法初始化自己的渠道code(方便工厂筛选),最后就是到了选择器,选择器呢我们是通过一个EnumMap来实现的,key就是渠道code,value就是对应的处理Handler(也就是策略实例),里面有putHandler()和route()方法;代码如下
/**
* channel->Handler的映射关系
*
* @author 3y
*/
@Component
public class HandlerHolder {
private Map<Integer, Handler> handlers = new HashMap<>(128);
public void putHandler(Integer channelCode, Handler handler) {
handlers.put(channelCode, handler);
}
public Handler route(Integer channelCode) {
return handlers.get(channelCode);
}
}
以上呢就是我们:工厂+策略模式将不同的消息渠道和推送中台映射逻辑解耦这一条的实现
工厂+责任链模式对消息过滤和校验进行优化 关于这个点要比上面的点简单一些
注意:责任链中判断是否继续的是消息任务中的一个NeedBreak标志,这个标志如果为False则直接打断 在我实习所负责的这个项目中,这个责任链模式主要体现在消息下发前的一系列检验处理(发送前置参数检验(消息模板ID、接收者是否为空或者数量太大)、组装参数(获取指定的消息模板,然后对占位符进行替换解析等、组装任务信息)、发送前的参数校验(手机号码邮件的合法性校验、正则表达式)、投递消息到MQ)和经过MQ处理之后【消息丢弃、消息去重、夜间屏蔽、、敏感词过滤、路由到对应的渠道下发消息】的去重限流的一些逻辑;主要实现如下
责任链模式主要有三个角色:
-
抽象处理者(Handler):定义了一个处理请求的接口,通常包括一个处理方法和一个指向下一个处理者的引用(nextHandler)。这个角色是责任链模式的核心,它规定了所有具体处理者必须遵循的契约。
-
具体处理者(Concrete Handler):继承或实现抽象处理者,负责处理特定类型的请求。每个具体处理者都会检查自己是否能够处理传入的请求,如果可以处理,则执行相应的动作;如果不能处理,则将请求传递给链上的下一个处理者。
-
客户端(Client):创建具体的处理者对象并将它们链接成一条链。客户端还负责将请求发送到责任链的起始点,即第一个具体处理者。客户端不需要关心请求的具体传递过程,只需知道如何设置和启动处理链
在我实习过程中,这个抽象处理者是一个接口,里面定义了一个处理方法,具体逻辑要让实现它的具体处理者实现,上面所说的那一系列处理Action都是实现了这个接口,串起来的话是使用一个【业务执行模板(把责任链的逻辑串起来)】,这个执行模板有个成员变量就是private List<BusinessProcess> processList;并且提供其get和set方法,他这个执行模板是从一个配置类中获取的,里面也是一个Map,key就是code,value就是执行模板;
注意:这里的执行责任链的顺序是定的,我们可以通过@Order注解来利用Spring注入特性,按照@Order从小到达排序注入到集合中
技能二:easyExcel优化导入导出
使用 EasyExcel 工具结合批量处理和 MQ 异步的方式实现用户客群信息的导入和导出,避免了大数据量操作导致的 OOM
优势: Apache poi、jxl。严重的问题就是非常的耗内存,解压后存储都是在内存中完成的,内存消耗依然很大。 easyexcel重写了poi对07版Excel的解析,一个3M的excel用POl sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;
导出:
循环导出:原始想法(百万数据太久了) 先一条条的读取数据放在一个list里边,然后用Apache的POI写入excel
批量查询导出(优化方案) 分页批量查询后汇总到一个excel中
Execel excel = new Excel();
for (int i=0;i< page;i++) {
List<data> data = getFromDB(i, pagesize);
excel.write(data);
}
excel.close();
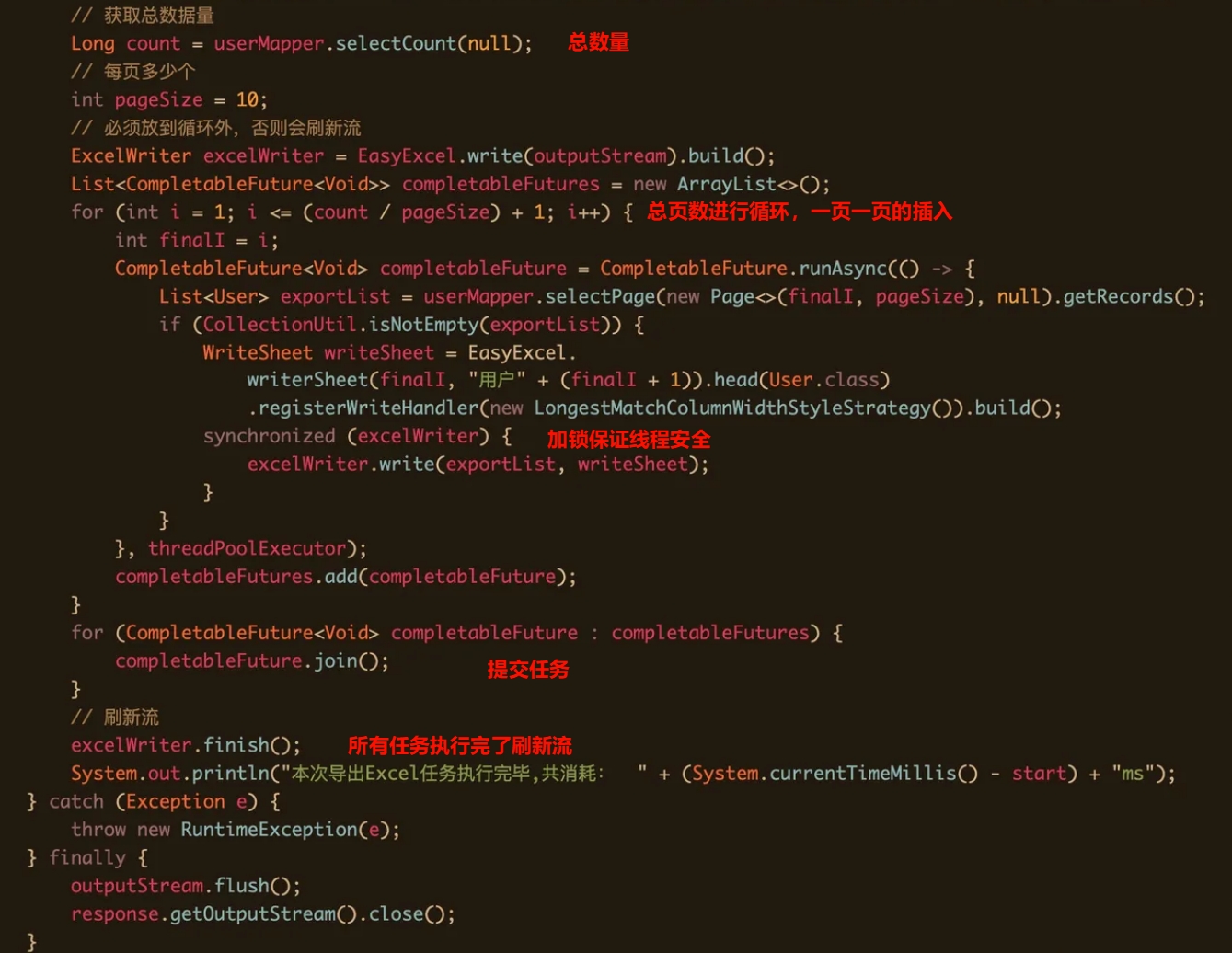
结合线程池优化
excel的最终写入完成是需要知道的,CompletableFuture这就派上了用场。只有全部的任务完成之后,才会刷新流,标志着excel的写入完成
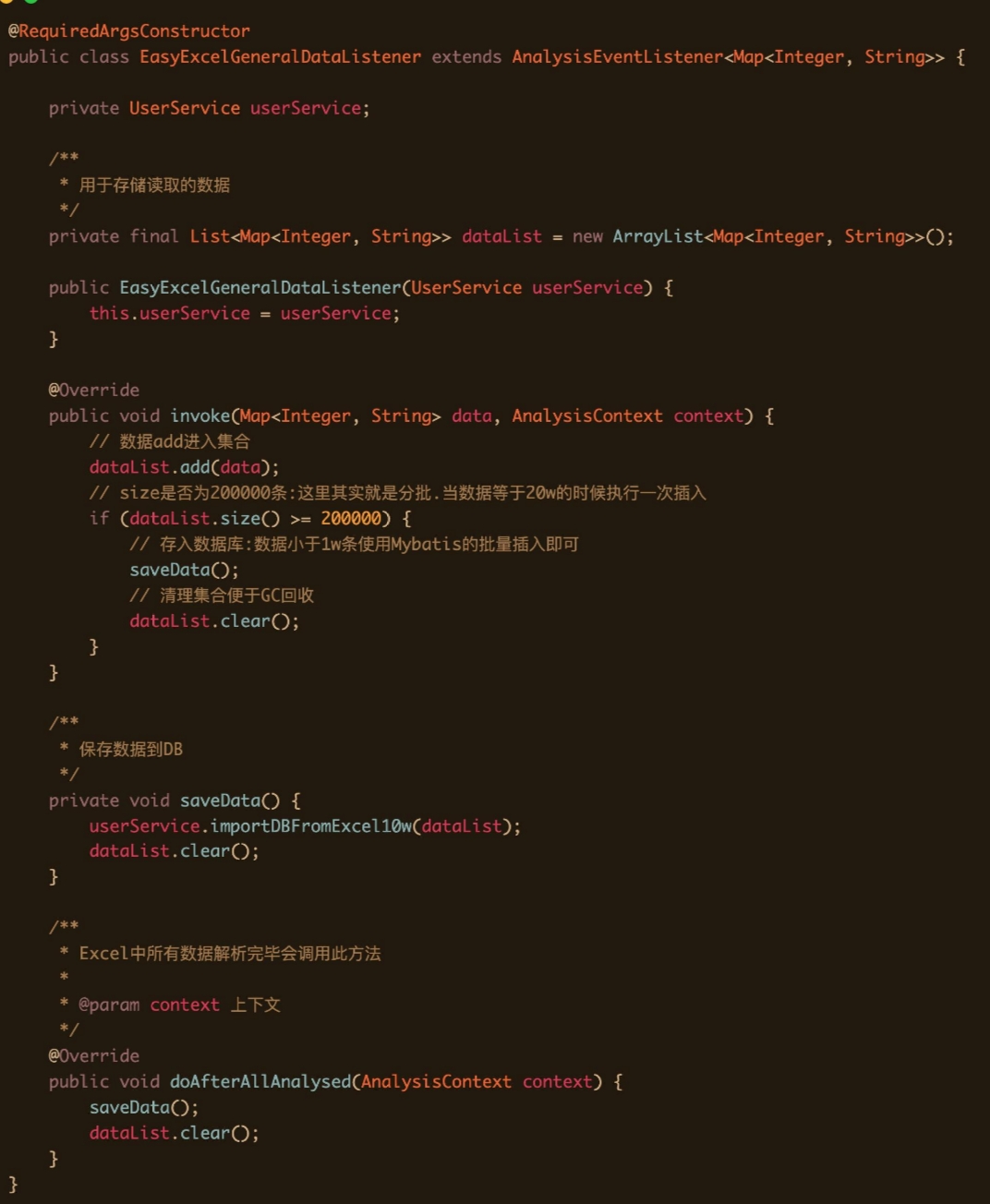
导入 从excel导入100万数据到mysql
- 首先是easyExcel分批读取Excel中的100w数据 EasyExcelGeneralDataListener按照sheet页一行行的数据读取
- 其次就是往DB里插入,怎么去插入这20w条数据,批量插入 同样也不能使用Mybatis的批量插入,会读取数据到内存中,事务整体提交
- 使用JDBC+事务的批量操作将数据插入到数据库(分批读取+JDBC分批插入+手动事务控制)
@GetMapping("/importExcel")
public void importExcel(@RequestParam("file") MultipartFile file) throws IOException {
if (file == null || file.isEmpty()) {
throw new RuntimeException("file为空");
}
InputStream inputStream = file.getInputStream();
// 记录开始读取Excel时间,也是导入程序开始时间
long startReadTime = System.currentTimeMillis();
log.info("------开始读取Excel的Sheet时间(包括导入数据过程):" + startReadTime + "ms------");
// 读取所有Sheet的数据.每次读完一个Sheet就会调用这个方法
EasyExcel.read(inputStream, new EasyExcelGeneralDataListener(userService)).doReadAll();
long endReadTime = System.currentTimeMillis();
log.info("------结束读取耗时" + (endReadTime - startReadTime) + "ms------");
}
使用MQ异步
-
用户点击全部导出按钮,会调用一个后端接口,该接口会向mq服务端,发送一条mq消息。
-
有个专门的mq消费者,消费该消息,然后就可以实现excel的数据导出了。
-
相较于job方案,使用mq方案的话,实时性更好一些。
-
对于mq消费者处理失败的情况,可以增加补偿机制,自动发起重试。
-
RocketMQ自带了失败重试功能,如果失败次数超过了一定的阀值,则会将该消息自动放入死信队列。
文件上传到OSS 由于现在我们导出excel数据的方案改成了异步,所以没法直接将excel文件,同步返回给用户。 因此我们需要先将excel文件存放到一个地方,当用户有需要时,可以访问到。 文件上传到OSS文件服务器上。,将excel上传成功后,会返回文件名称和访问路径。 我们可以将excel名称和访问路径保存到表中,这样的话,后面就可以直接通过浏览器,访问远程excel文件了。 而如果将excel文件保存到应用服务器,可能会占用比较多的磁盘空间。 一般建议将 应用服务器 和 文件服务器 分开,应用服务器需要更多的内存资源或者CPU资源,而文件服务器需要更多的磁盘资源。
技能四:保证消息的至少消费一次的语义
一、从Kafka拉取消息(一次批量拉取500条,这里主要看配置)
二、为每条拉取的消息分配一个msgld(递增)
三、将msgld存入内存队列(sortSet)中
四、使用Map存储msgld与msg(有offset相关的信息)的映射关系
五、当业务处理完消息后,ack时,获取当前处理的消息msgld,然后从sortSet删除该msgld(此时代表已经处理过了)
六、接着与sortSet队列的首部第一个ld比较(其实就是最小的msgld),如果当前msgld<=sortSet第一个ID,则提交当前offset
七、系统即便挂了,在下次重启时就会从sortSet首的消息开始拉取,实现至少处理一次语义
八、会有少量的消息重复,但只要下游做好幂等就OK了
技能五:Redis的lua脚本进行去重
频次去重
频次去重采用普通的计数去重方法,限制的是每天发送的条数。过期时间为24h
使用Redis的String
k是(前缀【FRE】 + 接收者ID【receiverID】 + 发送渠道ID【channelID】 )
v是 (发送消息的次数)
文案去重
文案去重采用的是新开发的基于redis中zset的滑动窗口去重,可以做到严格控制单位时间内的频次。
使用的是Redis的zset
key: (前缀【SW】 + MD5加密(消息模板ID + 接收者ID【receiverID】+ 发送文案的类型Code ) )
value: 雪花算法生成的唯一ID
score: 当前时间戳
lua脚本
--KEYS[1]: 限流 key
--ARGV[1]: 限流窗口,毫秒
--ARGV[2]: 当前时间戳(作为score)
--ARGV[3]: 阈值
--ARGV[4]: score 对应的唯一value
-- 1\. 移除开始时间窗口之前的数据
redis.call('zremrangeByScore', KEYS[1], 0, ARGV[2]-ARGV[1])
-- 2\. 统计当前元素数量
local res = redis.call('zcard', KEYS[1])
-- 3\. 是否超过阈值
if (res == nil) or (res < tonumber(ARGV[3])) then
redis.call('zadd', KEYS[1], ARGV[2], ARGV[4])
redis.call('expire', KEYS[1], ARGV[1]/1000)
return 0
else
return 1
end
滑动窗口的每个请求的时间记录可以利用 Redis 的zset存储,利用 zremrangeByScore,再用ZCARD 计数。
项目一:
利用 RabbitMQ 延时队列与 Redis 合并写请求方案实现了异步更新播放记录,实现秒级精度播放进度的回放
这个业务场景是我们要保存视频的播放记录,在我们数据库中有一个学习记录表,在这个业务中他的核心字段有,学习记录ID、视频进度、是否学完,初始方案是前端每十五秒提交一次播放精度的表单(如果数据库中不存在就要新增,存在的话就要更新对应的字段);这样带来的问题就是如果用户数据量上来了会造成大量的数据库查询io,以及连接数占用,阻塞其他业务对数据库的操作
使用自定义注解、AOP、SPEL 表达式实现基于注解的分布式锁,减少业务代码侵入的同时解决了优惠卷超发问题
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyLock {
String name();
long waitTime() default 1;
long leaseTime() default -1;
TimeUnit unit() default TimeUnit.SECONDS;
MyLockType lockType() default MyLockType.RE_ENTRANT_LOCK;
MyLockStrategy lockStrategy() default MyLockStrategy.FAIL_AFTER_RETRY_TIMEOUT;
}
首先我定义了一个@MyLock注解,里面有几个属性:
- 锁的名称、
- 等待时间、
- 超时时间、
- 时间单位、
- 锁类型(通过枚举实现:主要有可重入锁、公平锁、读锁、写锁)
- 锁的失败策略(快速结束、快速失败、无限重试、重试超时后结束、重试超时后失败)
锁失败策略:
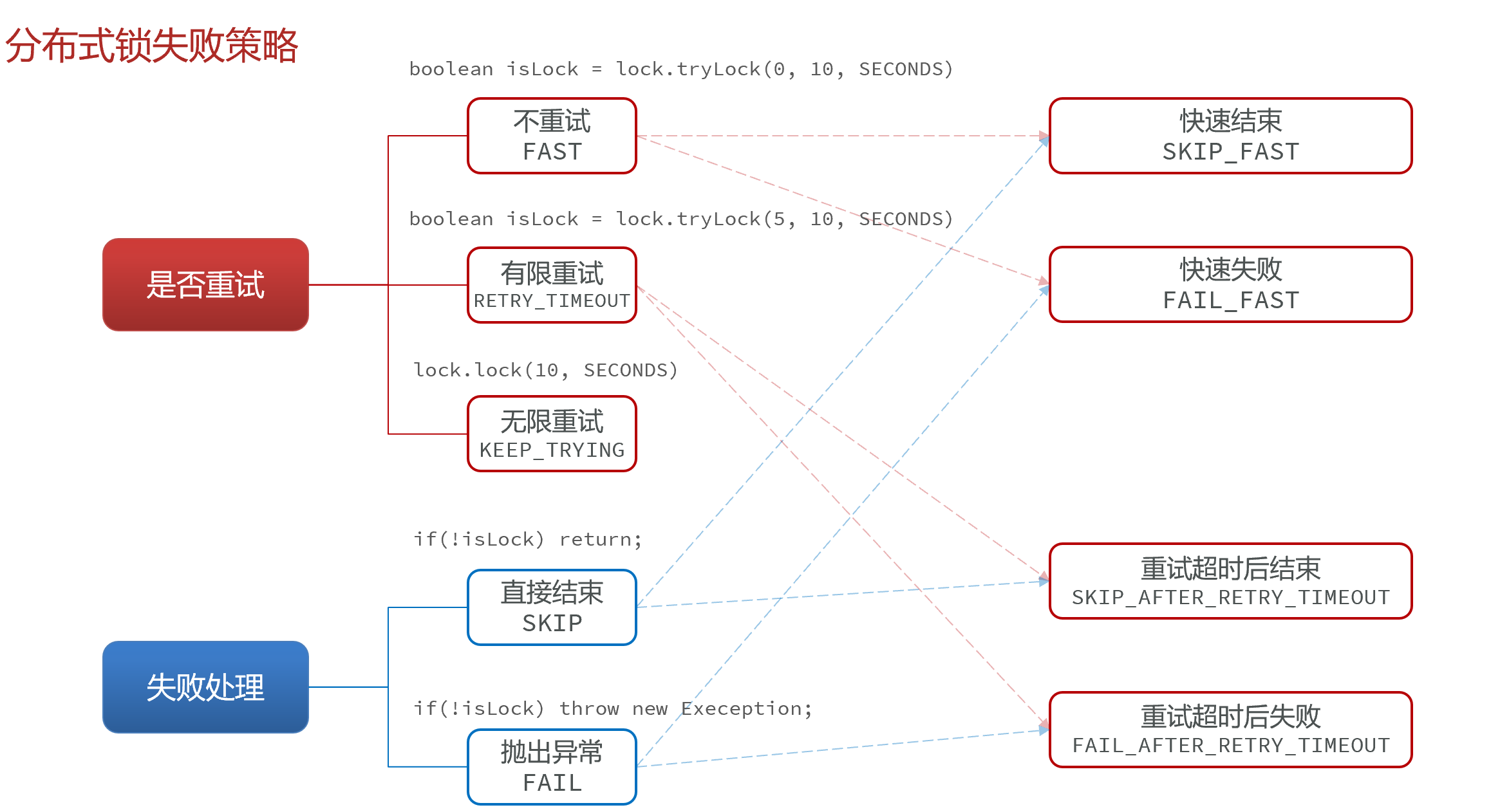
boolean isLock = lock.tryLock(waitTime,outTime,unit);
怎么组合起来的呢 就是获取锁的时候等待的三种选择:
- 等待时间 (waitTime)==0 的时候:不重试获取锁
- 等待时间 (waitTime)>0 的时候:在有限的时间内重试获取锁
- 不存在这个等待时间的参数也就是如下代码时,就是无限次重试
boolean isLock = lock.tryLock(outTime,unit);
锁获取失败的选择:
- 抛异常
- 直接return ** 以上方案两两组合就有五种方案(无限重试不组合)**
然后我定义了一个切面类
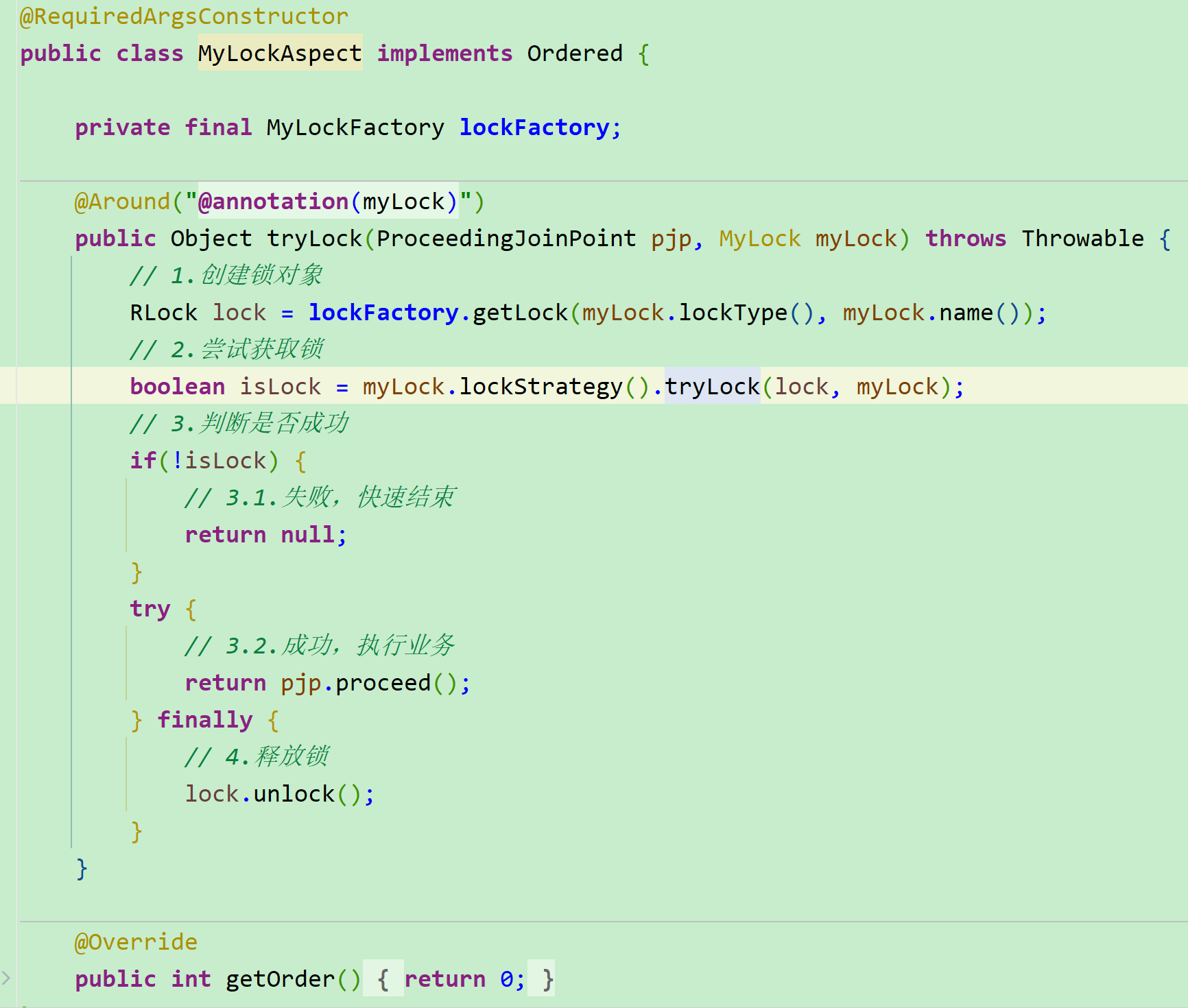
@Around作用的范围就是加的@MyLock注解的范围
切面类中做的工作就是我根据自己传进来的的注解参数(锁类型、锁名称),到对应的锁工厂(EnumsMap)获取对应类型的锁,然后就是根据具体的锁策略进行加锁;加锁成功后执行ProceedingJoinPoint.proceed()执行业务方法,并且进行try()catch()捕捉,在finally代码块中释放锁;
为什么使用Spel动态锁名称,spel的主要作用就是,让加锁名称在编译的时候就能获取指定的参数例如下图
有参数时:
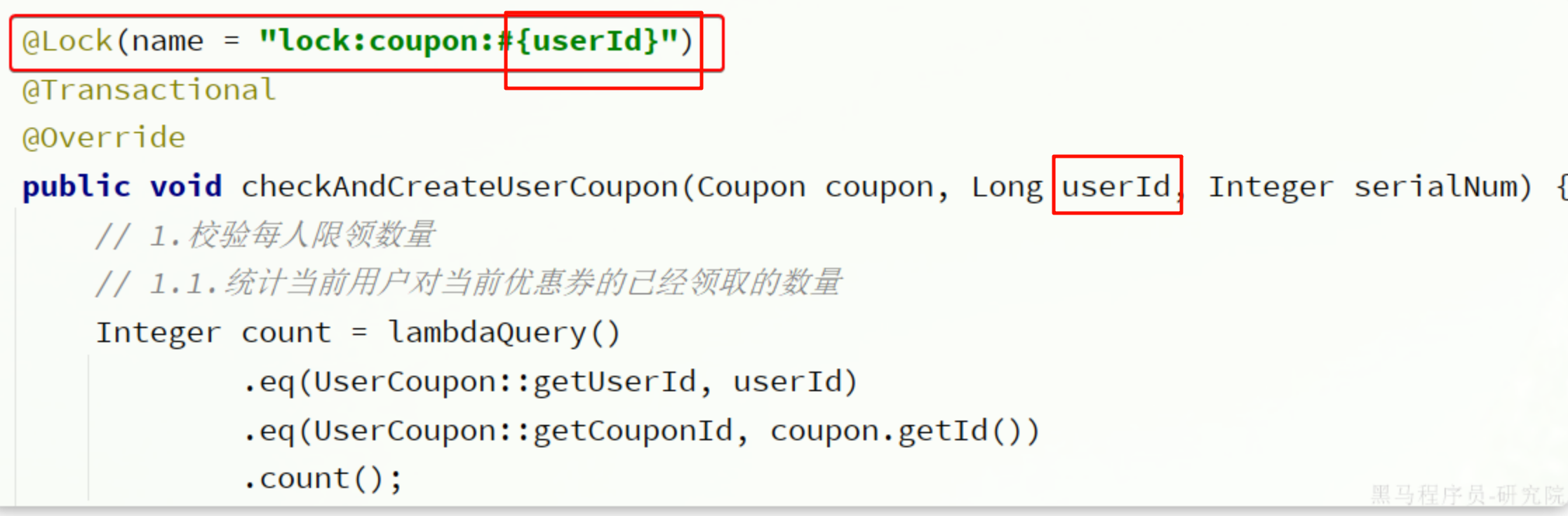 没有参数但可以获取时:
没有参数但可以获取时:T(类名).方法名() 须是静态方法获取







评论( 0 )