MySQL有哪几种索引类型?
1、从存储结构上来划分
- BTree索引(B-Tree或B+Tree索引)
- Hash索引
- full-index全文索引
- R-Tree索引
这里所描述的是索引存储时保存的形式
2、从应用层次来分:普通索引,唯一索引,复合索引。
- 普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,但允许有空值
- 复合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同
- 的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和
- 数据行。
- 非聚簇索引: 不是聚簇索引,就是非聚簇索引
3、根据中数据的物理顺序与键值的逻辑(索引)顺序关系: 聚集索引,非聚集索引。
4. 说一说索引的底层实现?
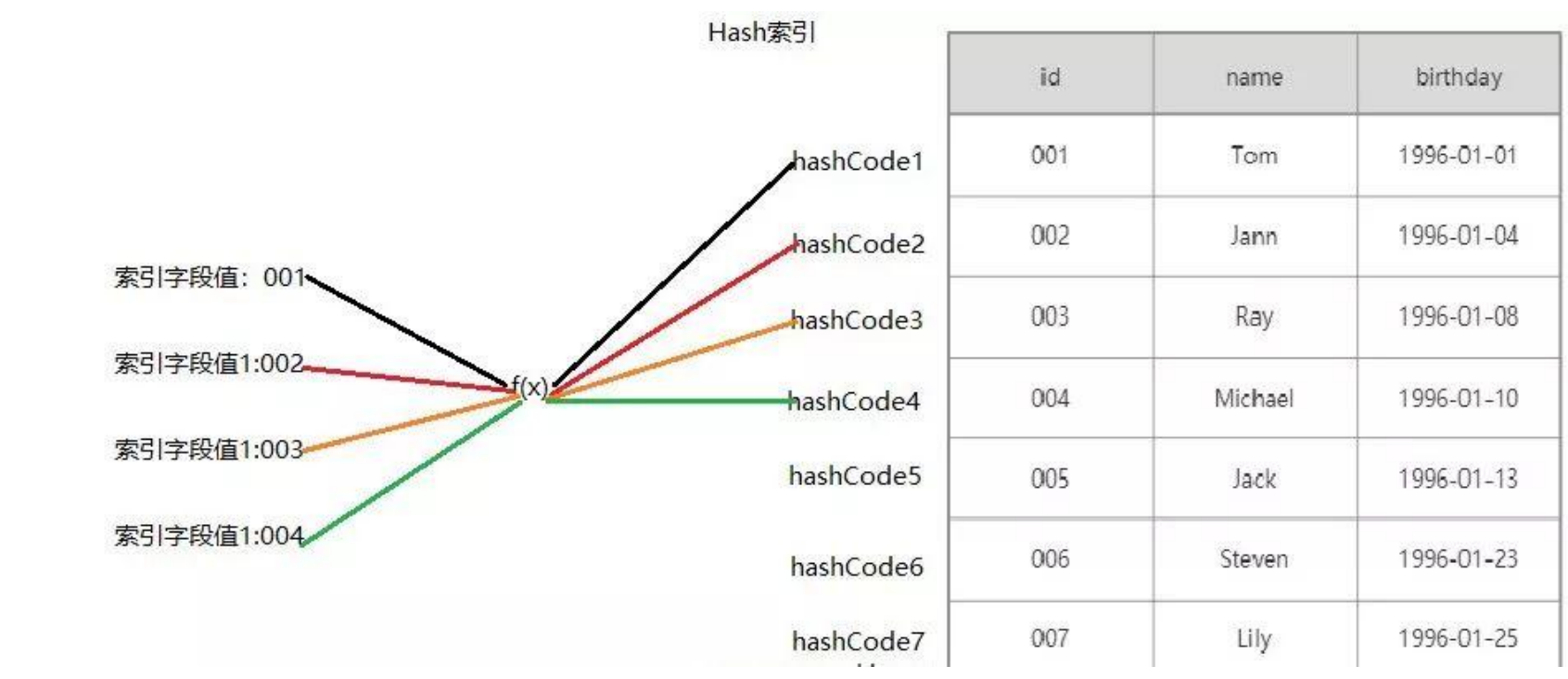
Hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。 图片来源:https://www.javazhiyin.com/40232.html
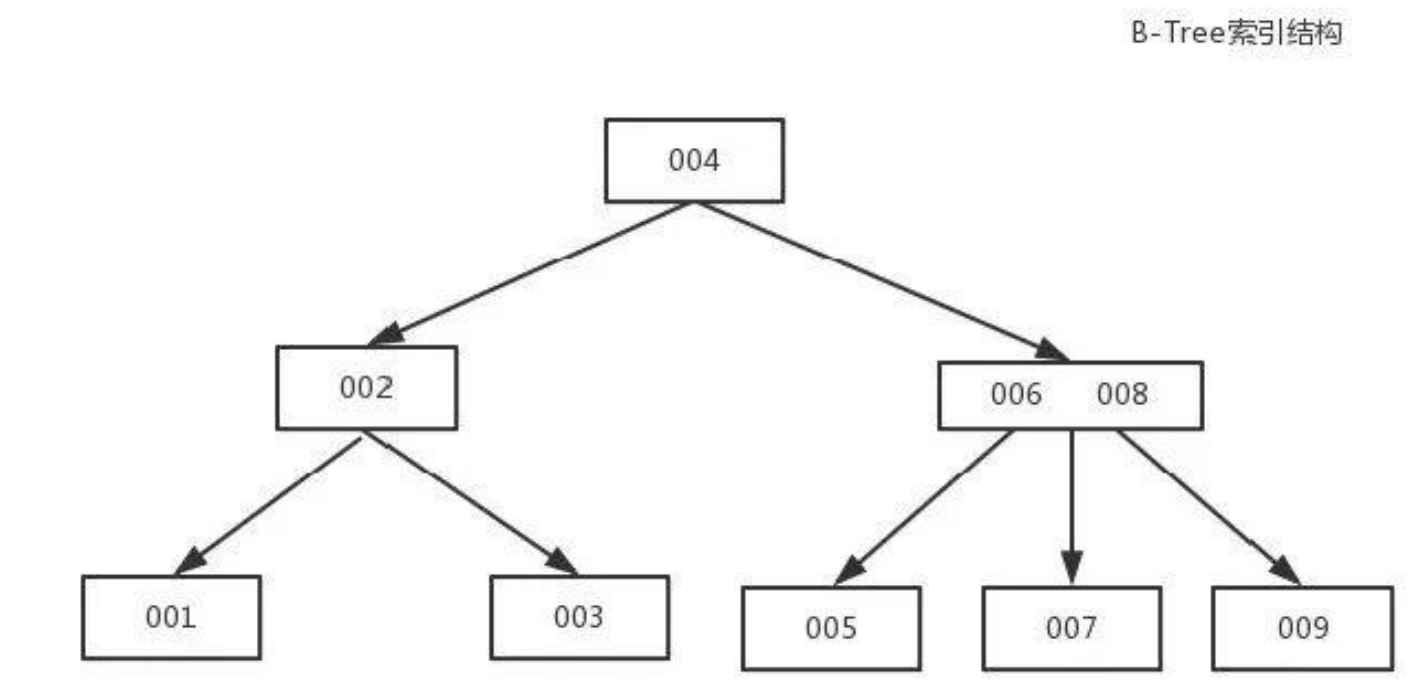
B-Tree索引(MySQL使用B+Tree)
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中
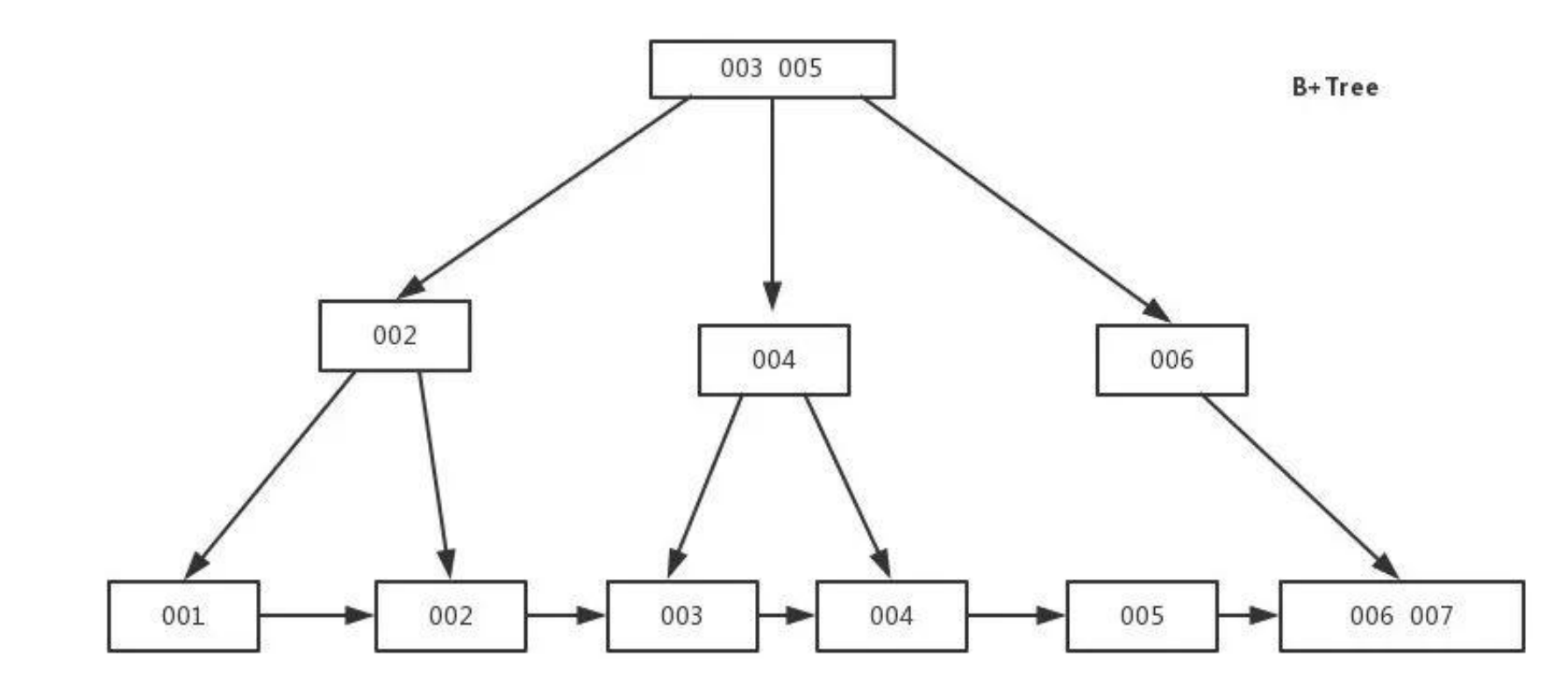
B+Tree索引
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
B+tree性质:
- n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
- 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依
- 关键字的大小自小而大顺序链接。
- 所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
- B+ 树中,数据对象的插入和删除仅在叶节点上进行。
- B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
5. 为什么索引结构默认使用B+Tree,而不是B-Tree,Hash,二叉树,红黑树?
B-tree: 从两个方面来回答
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B(B-)树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对 IO读写次数就降低 了。
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在 区间查询 的情况,所以通常B+树用于数据库索引。
Hash:
- 虽然可以快速定位,但是没有顺序,IO复杂度高;
- 基于Hash表实现,只有Memory存储引擎显式支持哈希索引 ;
- 适合等值查询,如=、in()、<=>,不支持范围查询 ;
- 因为不是按照索引值顺序存储的,就不能像B+Tree索引一样利用索引完成排序 ;
- Hash索引在查询等值时非常快 ;
- 因为Hash索引始终索引的所有列的全部内容,所以不支持部分索引列的匹配查找 ;
- 如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题 。
二叉树: 树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树: 树的高度随着数据量增加而增加,IO代价高。






评论( 0 )