Kafka 实现延迟消息方式
方式一:利用定时任务调度
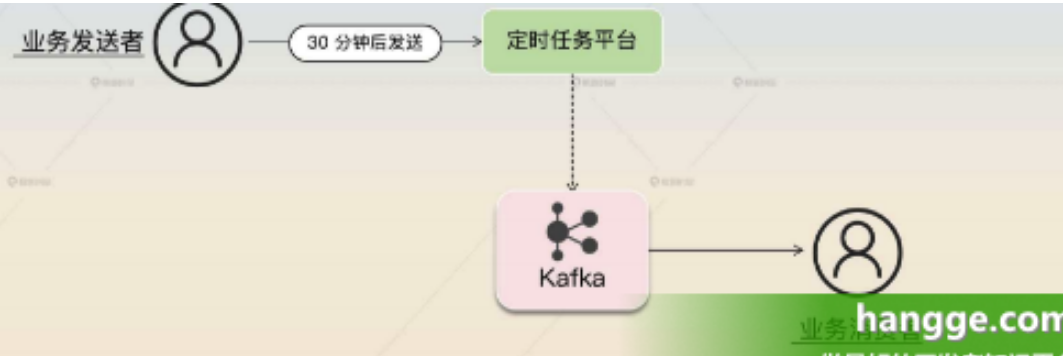
1.方案介绍 (1)利用定时任务来实现延迟消息是最好、最简单的办法。 对于一个延迟消息来说,一个延迟到 30 分钟后才可以被消费的消息,也可以认为是 30 分钟后才可以发送。也就是说,我们可以设定一个定时任务,这个任务会在 30 分钟后把消息发送到消息服务器上。
(2)定时任务调度最好是通过解决了持久化的分布式任务平台。那么业务发送者就相当于注册一个任务,这个任务就是在 30 分钟之后发送一条消息到 Kafka 上。之后业务消费者就能够消费了。
2.方案的缺点
这个方案的昀大缺点是支撑不住高并发。这是因为绝大多数定时任务中间件都没办法支撑住高并发、大数据的定时任务调度,所以只有应用规模小,延迟消息也不多的话,才可以考虑使用这个方案。如果想要支持高并发、大数据的延迟方案,还是要考虑利用消息队列。
方式2:分区设置不同延迟时间
1.方案介绍
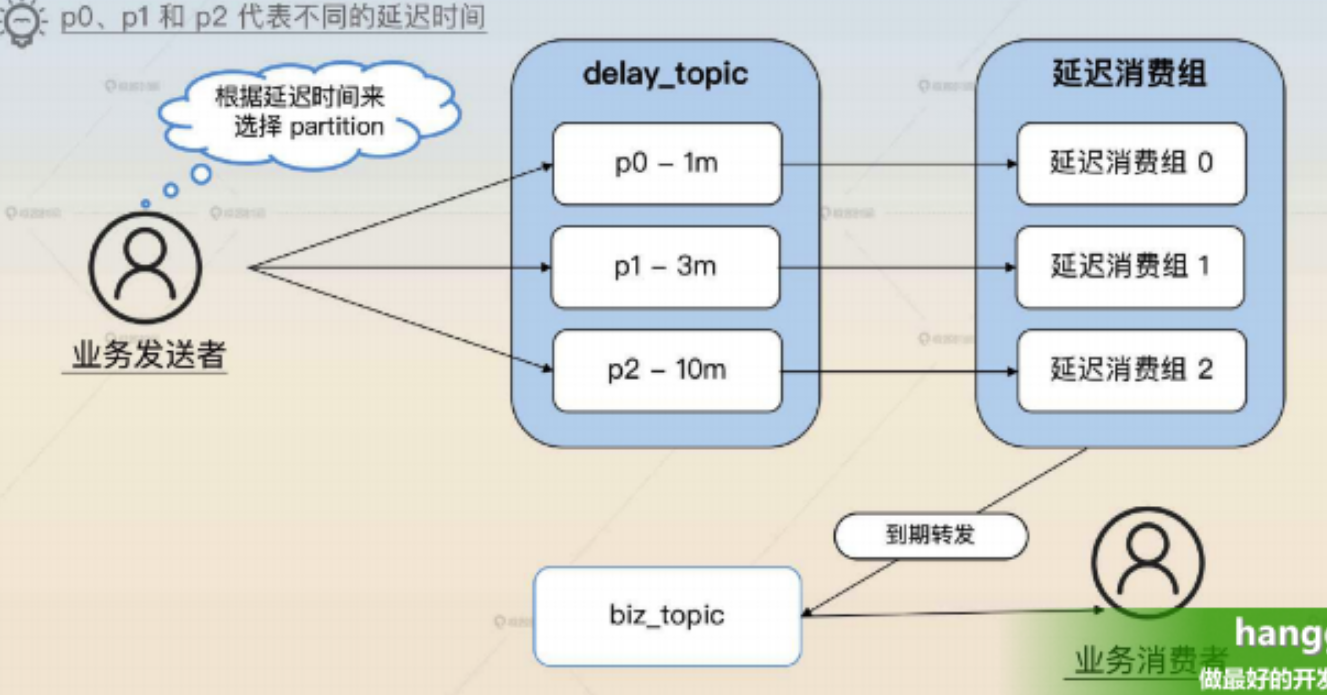
(1)该方案的基本架构图如下,这里关键的角色是 delay_topic 和延迟消费组:
-
创建了一个 delay_topic,这个topic有 N 个分区,每个分区设定了不同的延迟时间,用来接收不同延迟时间的消息。比如说在下图中分成了 p0、p1、p2 三个分区,分别用于接收延迟时间为 1min、3min 和 10min 的消息。
-
然后我们创建了一个消费组去消费这个 delay_topic,延迟消费组会创建出和分区数量一样的消费者,每一个消费者消费一个分区。每个消费者在读取到一条消息之后,就会根据消息里面的延迟时间来等待一段时间。等待完之后,再把消息发送到业务方真正的 topic 上(如下图的 biz_topic)
(2)其中分区 N 是根据业务来设计,比如:
- 5 个分区:延迟时间分别是 1min、3min、5min、10min、30min。
- 10 个分区:延迟时间分别是 1min、3min,5min、10min、15min、30min、60min、90min、120min、180min。
2.rebalance 问题 (1)在这个方案中,因为消费者睡眠了,睡眠期间不会消费消息,所以 Kafka 就会判定这个消费者已经崩溃了,从而触发 rebalance。等睡眠结束之后,重新消费,就不一定还是消费原本的那个分区了。
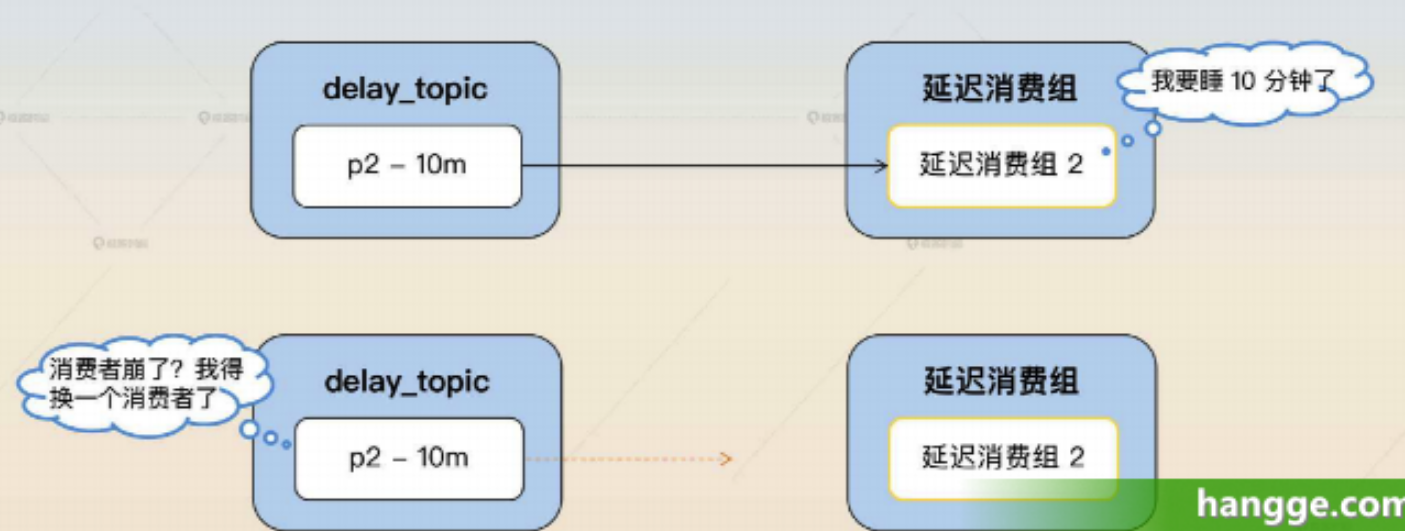
(2)为了避免这个问题,就需要确保在睡眠期间不会触发 rebalance。因此需要利用 Kafka 的暂停(Pause)功能,在睡眠结束之后,再恢复(Resume)。
提示:Kafka 的暂停消费,并不是不再发起 Poll 请求,而是 Poll 了但是不会真的拉消息,或者说相当于拉取 0 条数据。这样可以让 Kafka 始终认为消费者还活着。
(3)所以整体逻辑如下:
- 拉取一条消息,假如说 offset = N,查看剩余的延迟时间 t。
- 暂停消费,睡眠一段时间 t。
- 睡眠结束之后,恢复消费,继续从 offset = N 开始消费。
3,一致性问题 (1)从服务端拉取到消息,然后转发到 biz_topic 里面这个流程中,是先提交消息,还是先转发?
- 如果是先提交,那么就会出现消息提交了,但是还来不及转发 biz_topic 就宕机的情况,这显然不能容忍。
- 但是如果先转发 biz_topic,然后提交。那如果提交之前宕机了,后面恢复过来,又会转发一次。
(2)要解决一致性问题,必须先转发 biz_topic,然后再提交。同时还需要业务方的配合。
- 也就是说,如果在转发 biz_topic 之后,提交失败了,下一次就还可以重试,那么 biz_topic 就可能收到两条同样的消息。在这种场景下,就只能要求消费者做到幂等。
- 当然,即便不用延迟消息,消费者最好也要做到幂等的。因为发送方为了确保发送成功,本身就可能重试。
4,方案的优缺点 (1)优点:这个方案最大的优点就是足够简单,对业务方的影响很小,业务方只需要根据自己的延迟时间选择正确的分区就可以了。
(2)缺点:这个方案也有两个突出的缺点,就是延迟时间必须预先设定好、分区间负载不均匀。
-
第一个是延迟时间必须预先设定好,比如只能允许延迟 1min、3min 或者 10min 的消息,不支持随机延迟时间。在一些业务场景下,需要根据具体业务数据来计算延迟时间,那么这个就不适用了。
-
第二个是分区之间负载不均匀。比如很多业务可能只需要延迟 3min,那么 1min 和 10min 分区的数据就很少。这会进一步导致一个问题,就是负载高的分区会出现消息积压的问题。
提示:在这里,很多解决消息积压的手段都无法使用,所以只能考虑多设置几个延迟时间相近的分区,比如说在 3min 附近设置 2min30s,3min30s 这种分区来分摊压力。
方式3:基于MySQL转储方案
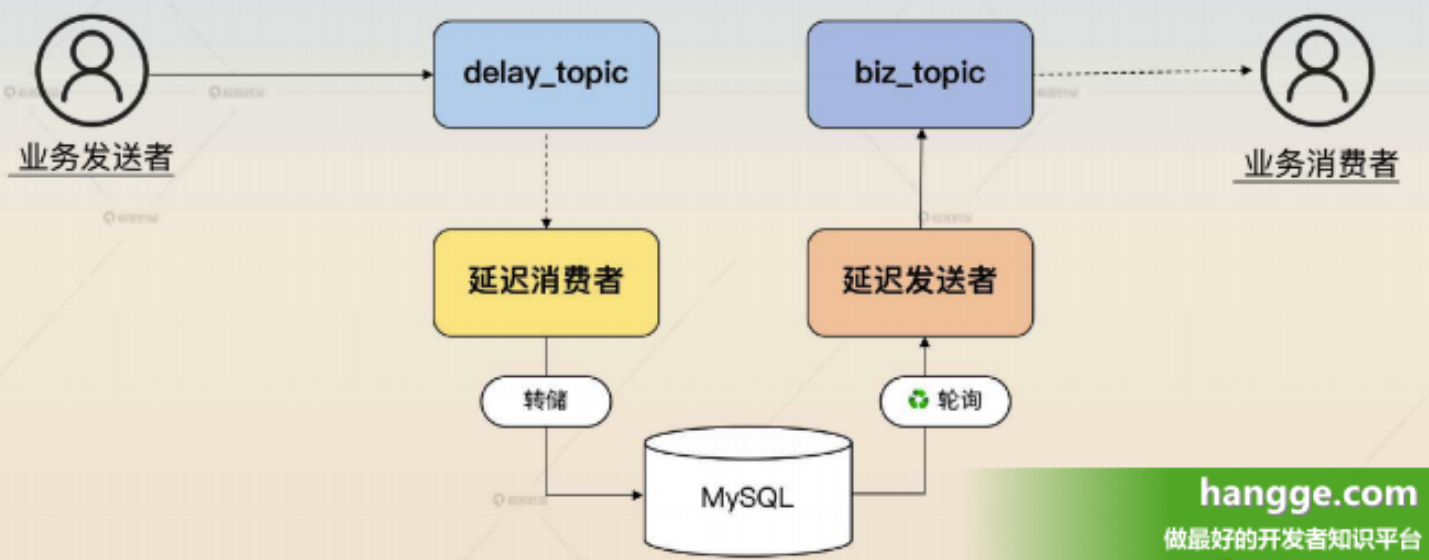
1,方案介绍 (1)该方案的实现逻辑如下:
- 创建一个 delay_topic,业务发送者把消息发送到这个 topic 里面,消息里面带上了需要延迟的时间。
- 有一个延迟消费者,它会消费 delay_topic 里面的消息,转储到数据库中。
- 还有一个延迟发送者,它会轮询数据库里的消息,把已经可以转发出去的消息转发到真正的 biz_topic 上。发送完之后,延迟发送者把数据库的状态更新成已发送。
- 最后业务消费者消费 biz_topic。
(2)如何支撑住高并发是该方案要解决的一个痛点。由于此方案最明显的性能瓶颈就是 MySQL,因为这个场景是一个写密集的场景。所以要想撑住高并发就要想办法提高 MySQL 的性能。
- 当然最佳的策略还是换一个存储结构,比如说换 TiDB 或者 Elasticsearch。
- 如果一定要使用 MySQL 的话,可以采用分区表、表交替、分库分表、批量操作几个优化方案。
2,分区表
(1)最简单的优化方案就是使用分区表,因为延迟消息是一个时效性很强的数据,也就是说,我们完全可以按照发送时间,也就是延迟之后具体的发送时间点来分区。
(2)分区表根据并发量选择按月分、按周分、按天分(例如在并发不是很高的时候,可以按照周来分区。在并发很高的时候,可以按照天来分区)。历史分区就可以直接清理掉。
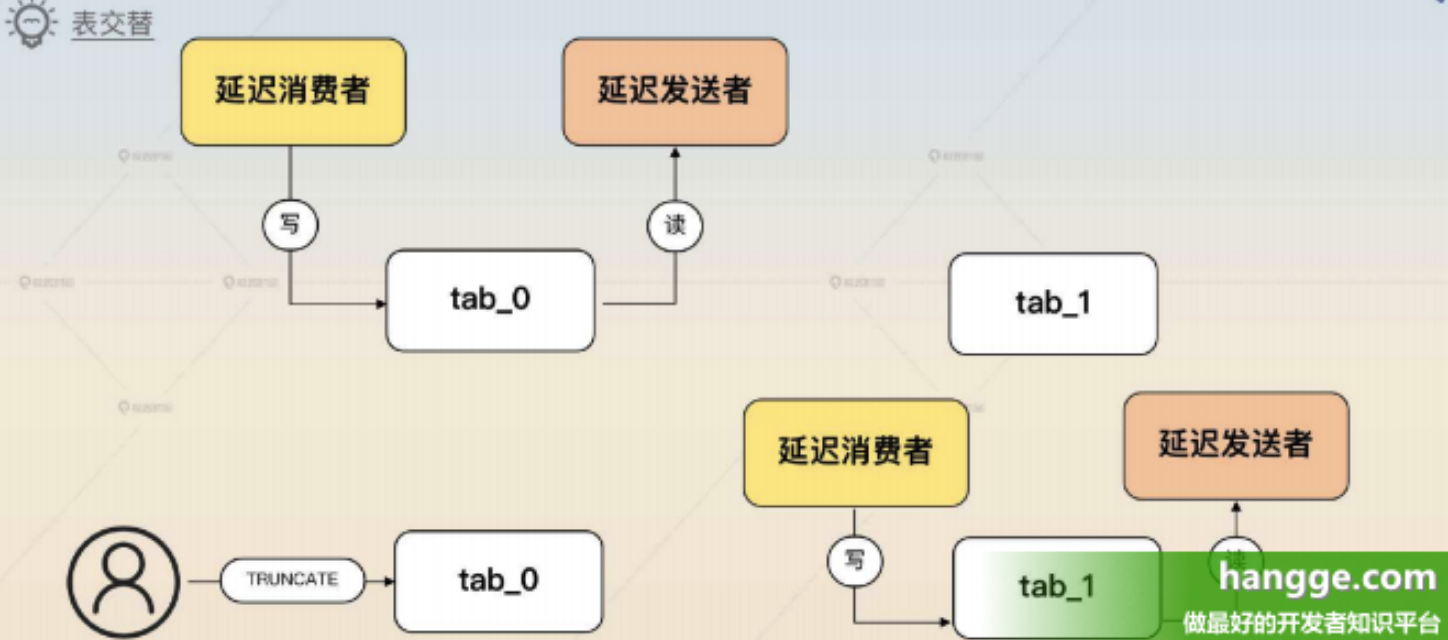
3,表交替
表交替方案的意思是准备两个表,然后交替写、交替查询。
- 比如准备两个表 tab_0、tab_1,今天用 tab_0,明天用 tab_1。当用 tab_1 的时候就可以直接清空(TRUNCATE)tab_0 的数据,反过来也是这样。TRUNCATE 本身很快,所以没什么性能问题。
- 这种按天交替的方案对延迟时间是有限制的,延迟时间不能超过一天。
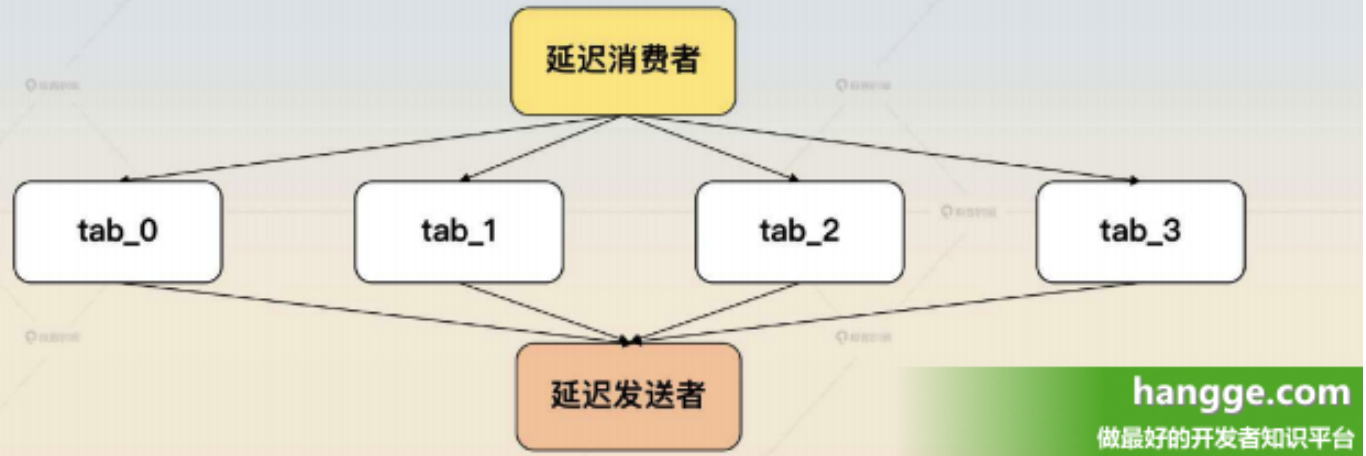
4,分库分表 (1)如果并发确实非常高,那么就只能考虑采用分库分表的方案了。这里分库分表也很简单,只需要按照 biz_topic 的名字来分库分表就可以了。而且每一张表可以叠加前面的分区表和交替表的方案,进一步提高性能。
(2)不过这个方案也有一定的隐患,第一个问题就是不同 topic 的并发度不一样,比如说 biz_topic_1 的并发只有 100,而 biz_topic_2 的并发有 10000,那么按照 biz_topic 来分,就会出现不同库不同表的压力差异很大的问题。
- 要解决这个问题,如果不考虑消息有序性的问题,那么也可以考虑轮询。比如说分库分表是 4 * 8 = 32 张表,那么就可以要求每一个延迟消费者,轮流往这些表里插入数据。因为延迟消息有一个很显著的特点,就是查找的时候只会按照发送时间来找,所以随机插入都没问题。
- 比如说我有一个消息发送给 biz_topic_1,要求是一分钟后发出去。那么不管这个消息被存在哪个表,延迟发送者都可以找出来,然后转发到biz_topic_1。
5,批量操作 (1)我们还可以利用批量操作来减轻 MySQL 的压力。对于延迟消费者来说,它可以消费了一批数据之后再批量插入到数据库里面,然后再提交这一批消息。对于延迟发送者来说,当发送了一批数据之后,再批量把这些消息更新为已发送。
(2)批量操作方案类似于分区设置不同延时时间方案,会使数据一致性问题更加严重,不过只需要消费者做到幂等就可以了。因为本质上,这里的一致性问题要么是因为延迟消费者重复消费,要么就是因为延迟发送者重复发送。但不管是哪个原因,消费者幂等都可以解决问题。






评论( 0 )