前言
在上一篇文章中我们用synchronized解决的用户领取优惠卷超卖的问题:项目一总结:(十)优惠卷超卖问题的解决(1)
但是真的就到此为止了嘛?
问题
这是在我们单机模式下没有超卖的问题,我们的服务将来肯定会多实例,形成集群。每一个实例都会有一个自己的JVM运行环境,因此即便是同一个用户,如果并发的发起了多个请求,由于请求进入了多个JVM,就会出现多个锁对象(用户id对象),自然就有多个锁监视器。此时就会出现每个JVM内部都有一个线程获取锁成功的情况,没有达到互斥的效果,并发安全问题就可能再次发生了。

关于最后的方式呢,我们是使用的Redisson这个成熟的分布式锁框架,我单独总结了一篇文章,讲述了synchronized这种基于JVM层面的锁的缺点,以及Redis方案的部分缺点,最终如何选型的Redisson:请看 -> 集群下的锁失效问题
方案
项目集成了Redisson
几个关键点:
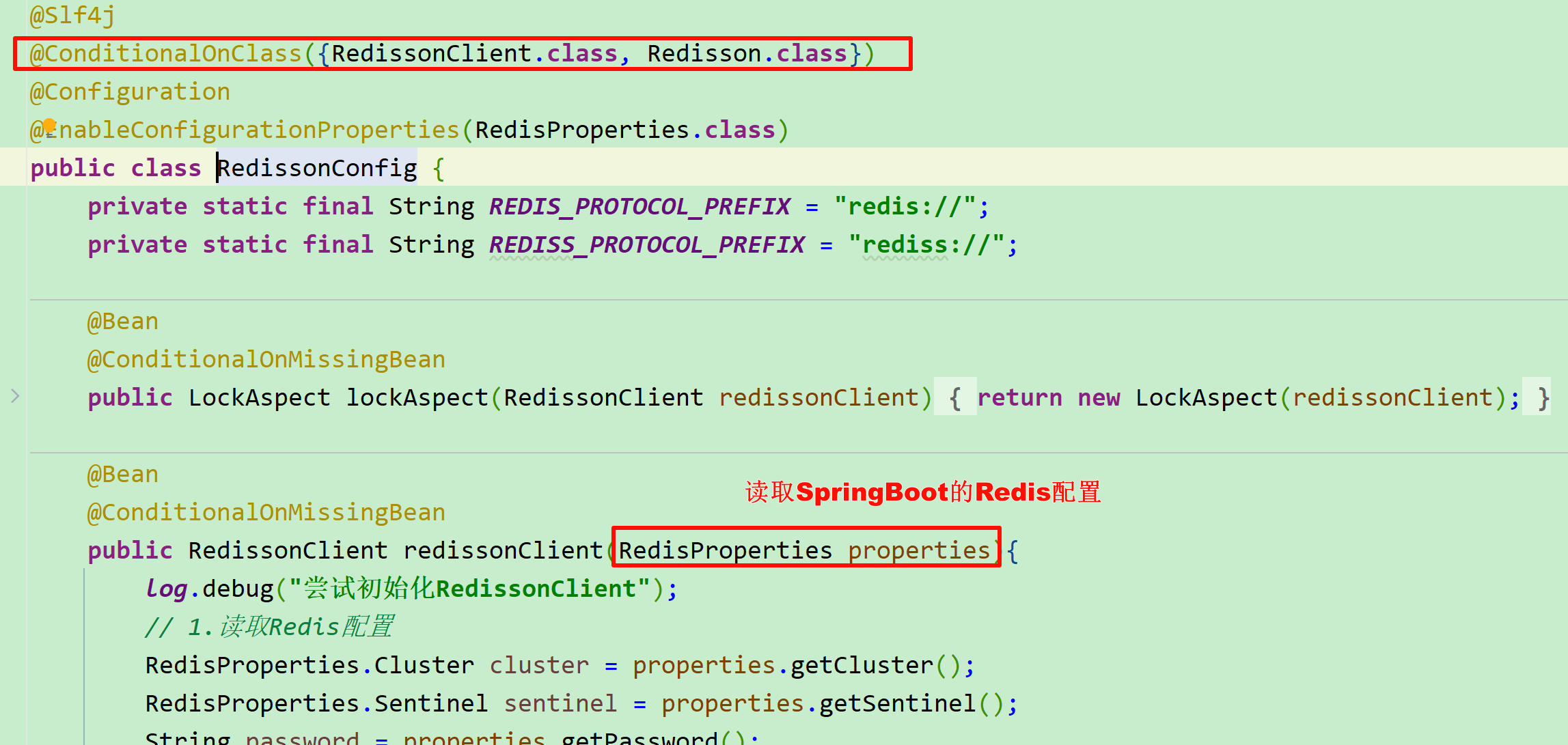
- 这个配置上添加了条件注解
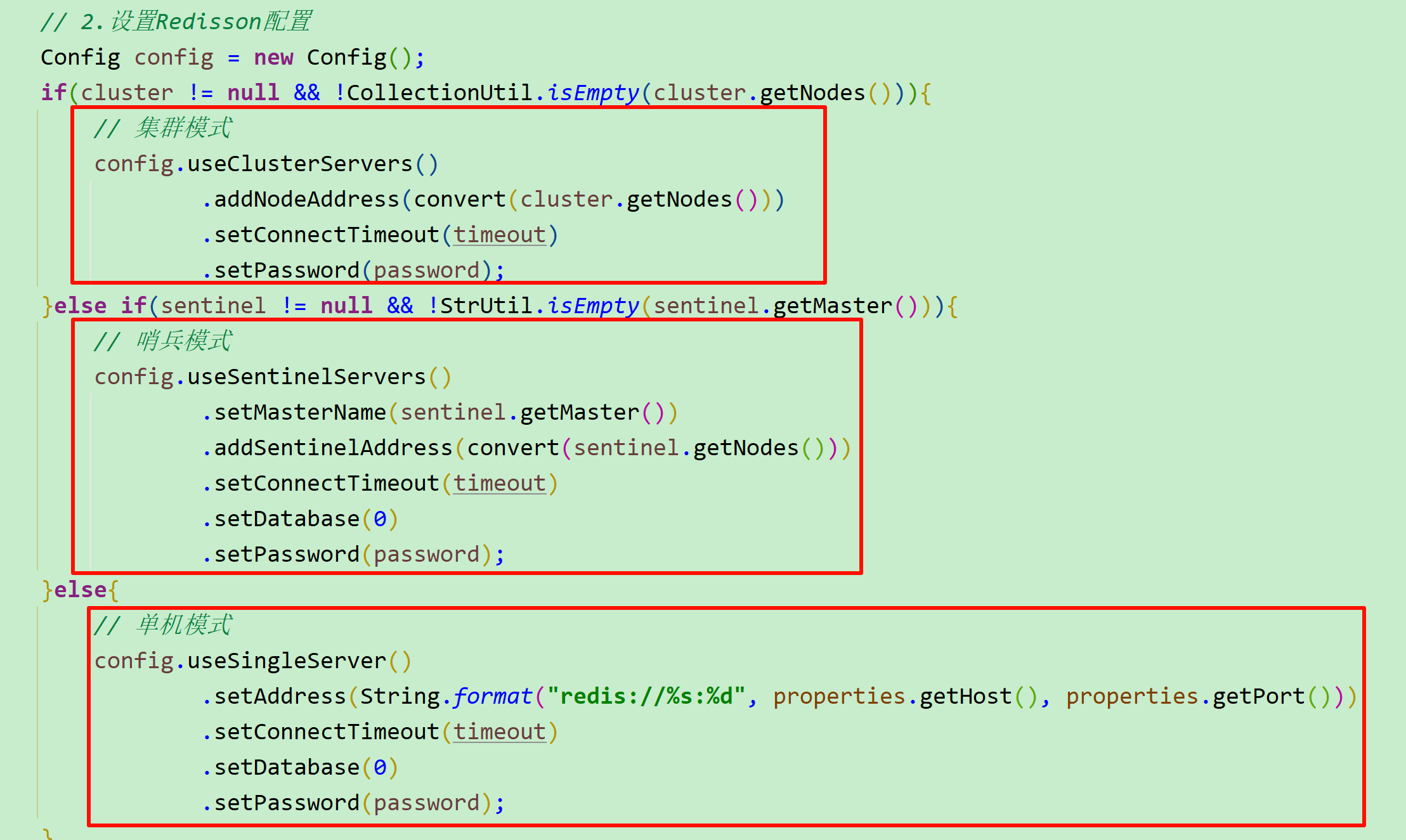
@ConditionalOnClass({RedissonClient.class, Redisson.class})也就是说,只要 引用了tj-common,并且引用了Redisson依赖,这套配置就会生效 。不引入Redisson依赖,配置自然不会生效,从而实现 按需引入 。 - RedissonClient的配置无需自定义Redis地址,而是直接基于SpringBoot中的Redis配置即可。而且不管是Redis单机、Redis集群、Redis哨兵模式都可以支持
代码改造
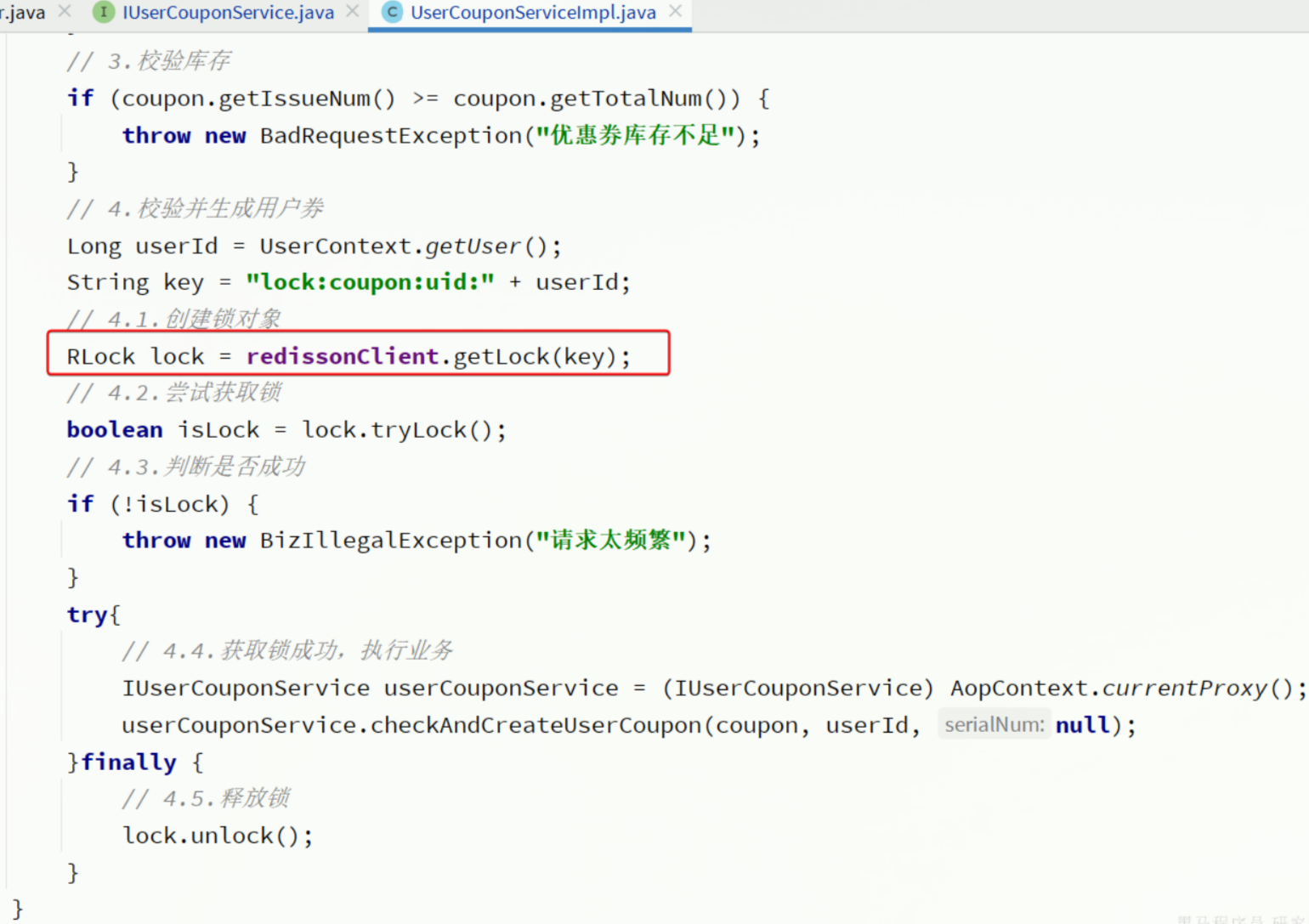
优化
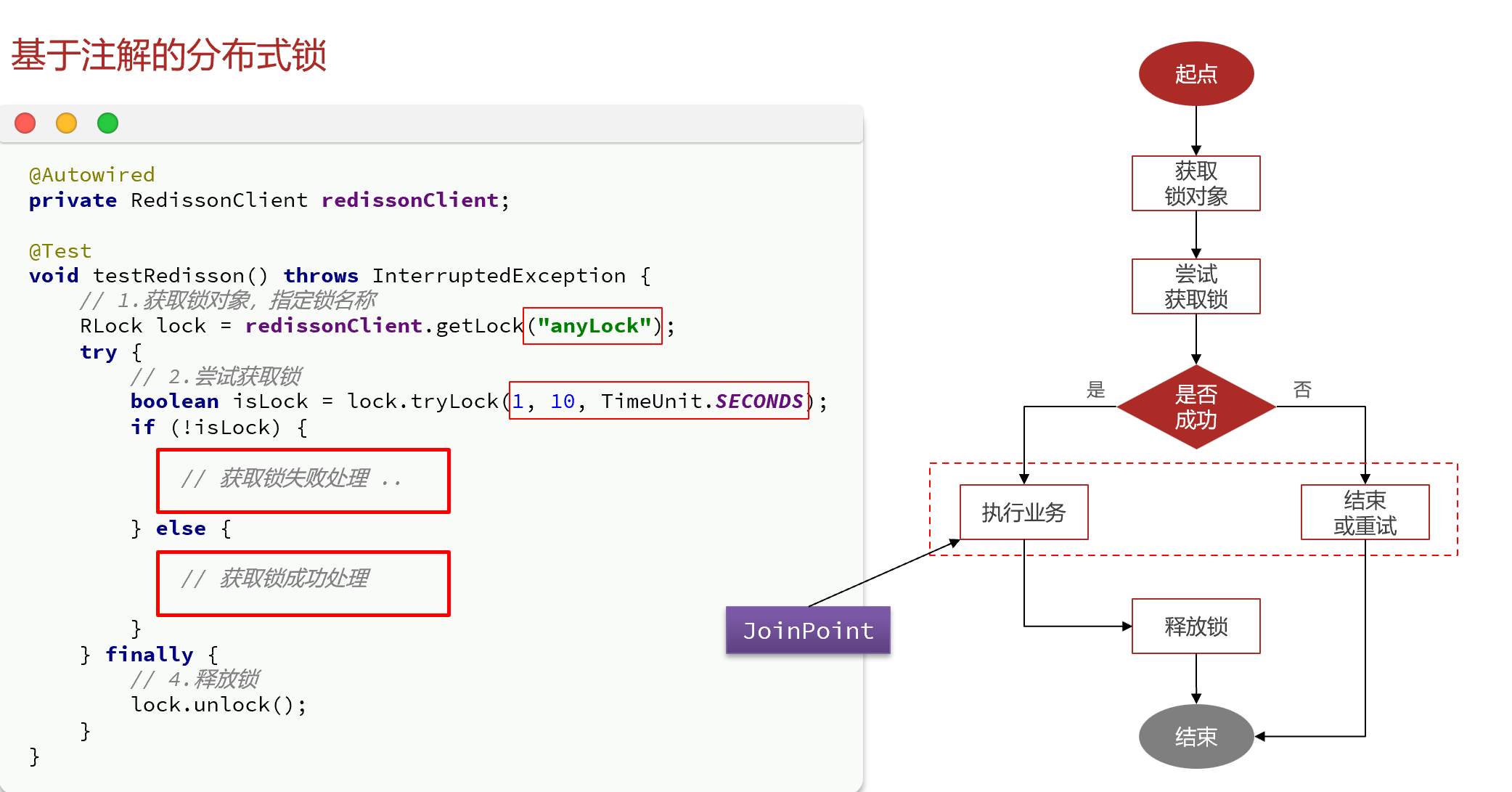
可以发现,只有红框部分是业务功能,业务前、后都是固定的锁操作。既然如此,我们完全可以基于AOP的思想,将业务部分作为切入点,将业务前后的锁操作作为环绕增强。
但是,我们该如何标记这些切入点呢?
不是每一个service方法都需要加锁,因此我们不能直接基于类来确定切入点;另外,需要加锁的方法可能也较多,我们不能基于方法名作为切入点,这样太麻烦。因此,最好的办法是把加锁的方法给标记出来,利用标记来确定切入点。如何标记呢?
最常见的办法就是基于注解来标记了。同时,加锁时还有一些参数,比如:锁的key名称、锁的waitTime、releaseTime等等,都可以基于注解来传参。
因此,注解的核心作用是两个:
- 标记切入点
- 传递锁参数
综上,我们计划利用注解来标记切入点,传递锁参数。同时利用AOP环绕增强来实现加锁、释放锁等操作。
定义注解
注解本身起到标记作用,同时还要带上锁参数:
- 锁名称
- 锁等待时间
- 锁超时时间
- 时间单位
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyLock {
String name();
long waitTime() default 1;
long leaseTime() default -1;
TimeUnit unit() default TimeUnit.SECONDS;
}
定义切面
接下来,我们定义一个环绕增强的切面,实现加锁、释放锁:
@Component
@Aspect
@RequiredArgsConstructor
public class MyLockAspect implements Ordered{
private final RedissonClient redissonClient;
@Around("@annotation(myLock)")
public Object tryLock(ProceedingJoinPoint pjp, MyLock myLock) throws Throwable {
// 1.创建锁对象
RLock lock = redissonClient.getLock(myLock.name());
// 2.尝试获取锁
boolean isLock = lock.tryLock(myLock.waitTime(), myLock.leaseTime(), myLock.unit());
// 3.判断是否成功
if(!isLock) {
// 3.1.失败,快速结束
throw new BizIllegalException("请求太频繁");
}
try {
// 3.2.成功,执行业务
return pjp.proceed();
} finally {
// 4.释放锁
lock.unlock();
}
}
@Override
public int getOrder() {
return 0;
}
}
注意,Spring中的AOP切面有很多,会按照Order排序,按照Order值从小到大依次执行。Spring事务AOP的order值是Integer.MAX_VALUE,优先级最低。
我们的分布式锁一定要先于事务执行,因此,我们的切面一定要实现Ordered接口,指定order值小于Integer.MAX_VALUE即可。
使用注解锁
定义好了锁注解和切面,接下来就可以改造业务了:
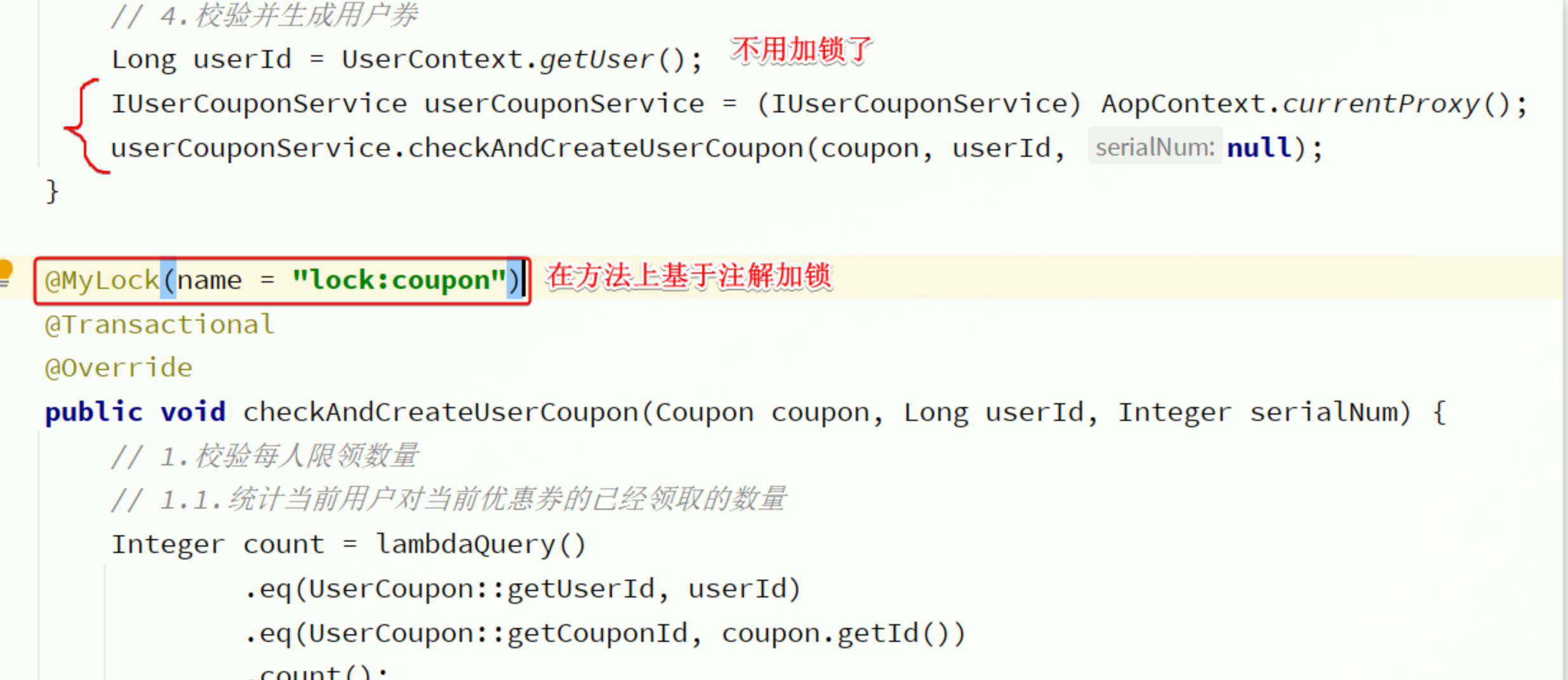
现在还存在几个问题:
- Redisson中锁的种类有很多,目前的代码中把锁的类型写死了
- Redisson中获取锁的逻辑有多种,比如获取锁失败的重试策略,目前都没有设置
- 锁的名称目前是写死的,并不能根据方法参数动态变化
工厂模式切换锁类型
Redisson中锁的类型有多种,例如:
因此,我们不能在切面中把锁的类型写死,而是交给用户自己选择锁类型。
那么问题来了,如何让用户选择锁类型呢?
锁的类型虽然有多种,但 类型是有限的几种,完全可以通过枚举定义出来。然后把这个枚举作为MyLock注解的参数,交给用户去选择自己要用的类型。
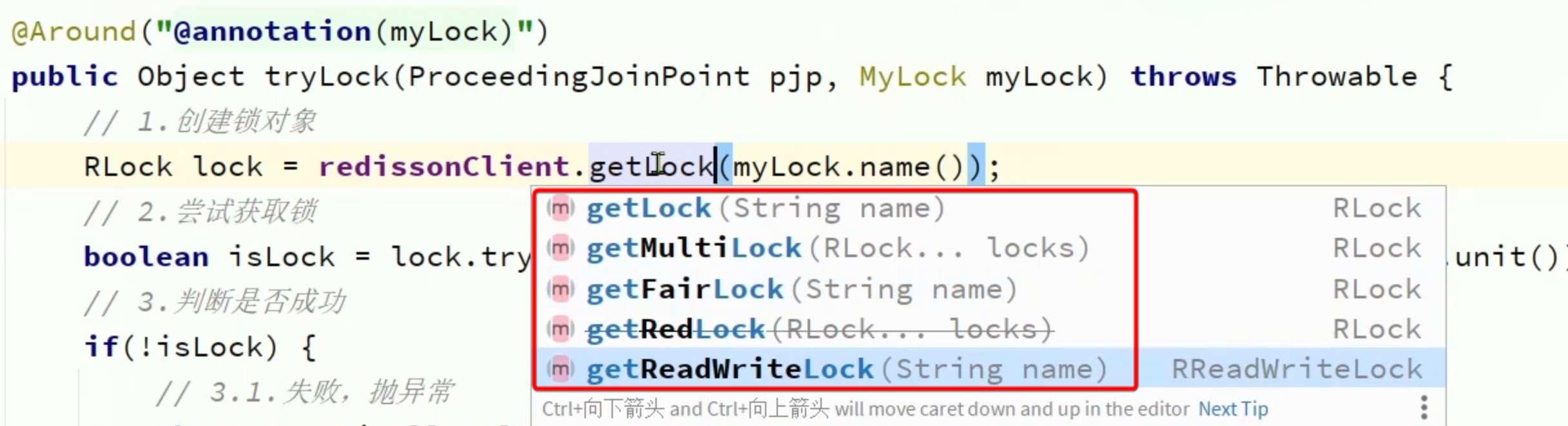
而在切面中,我们则需要根据用户选择的锁类型,创建对应的锁对象即可。但是这个逻辑不能通过if-else来实现,太low了。
这里我们的需求是 根据用户选择的锁类型,创建不同的锁对象 。有一种设计模式刚好可以解决这个问题:简单工厂模式。
锁类型枚举
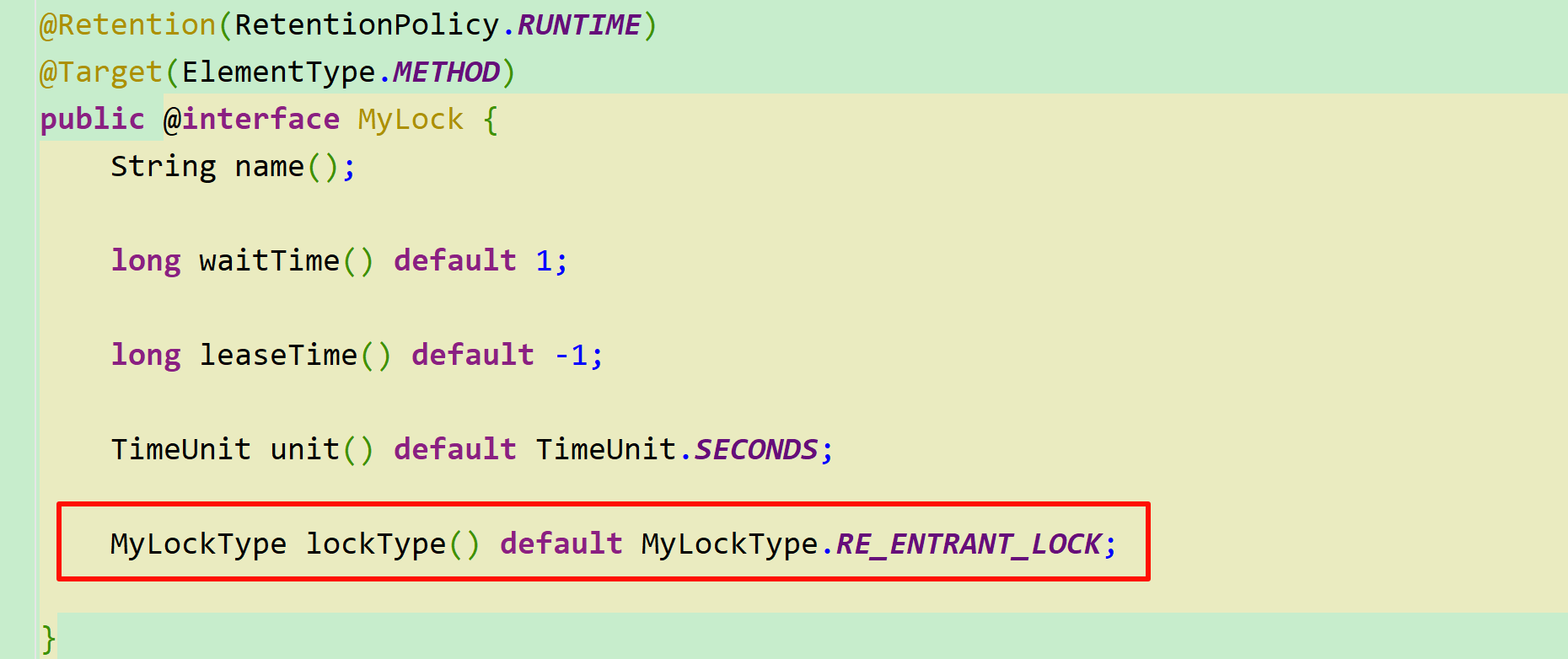
我们首先定义一个锁类型枚举:
public enum MyLockType {
RE_ENTRANT_LOCK, // 可重入锁
FAIR_LOCK, // 公平锁
READ_LOCK, // 读锁
WRITE_LOCK, // 写锁
;
}
锁对象工厂
然后定义一个锁工厂,用于根据锁类型创建锁对象:
@Component
public class MyLockFactory {
private final Map<MyLockType, Function<String, RLock>> lockHandlers;
public MyLockFactory(RedissonClient redissonClient) {
this.lockHandlers = new EnumMap<>(MyLockType.class);
this.lockHandlers.put(RE_ENTRANT_LOCK, redissonClient::getLock);
this.lockHandlers.put(FAIR_LOCK, redissonClient::getFairLock);
this.lockHandlers.put(READ_LOCK, name -> redissonClient.getReadWriteLock(name).readLock());
this.lockHandlers.put(WRITE_LOCK, name -> redissonClient.getReadWriteLock(name).writeLock());
}
public RLock getLock(MyLockType lockType, String name){
return lockHandlers.get(lockType).apply(name);
}
}
MyLockFactory内部持有了一个Map,key是锁类型枚举,值是创建锁对象的Function。注意这里 不是存锁对象,因为锁对象必须是多例 的, 不同业务用不同锁对象 ;同一个业务用相同锁对象。MyLockFactory内部的Map采用了EnumMap。只有当Key是枚举类型时可以使用EnumMap,其底层不是hash表,而是简单的数组。由于枚举项数量固定,因此这个数组长度就等于枚举项个数,然后按照枚举项序号作为角标依次存入数组。这样就能根据枚举项序号作为角标快速定位到数组中的数据。
改造切面代码
我们将锁对象工厂注入MyLockAspect,然后就可以利用工厂来获取锁对象了:
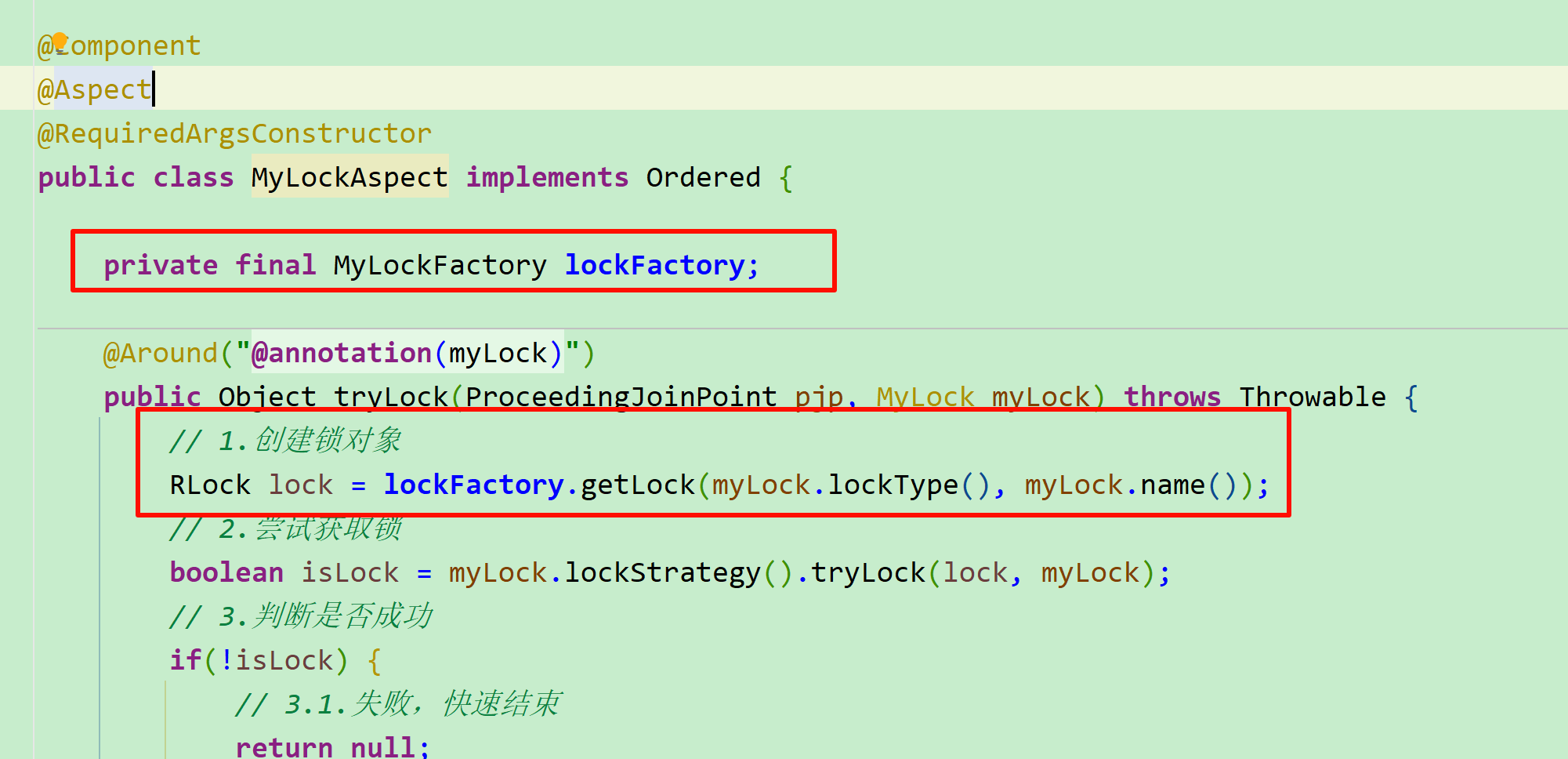
此时,在业务中,就能通过注解来指定自己要用的锁类型了:
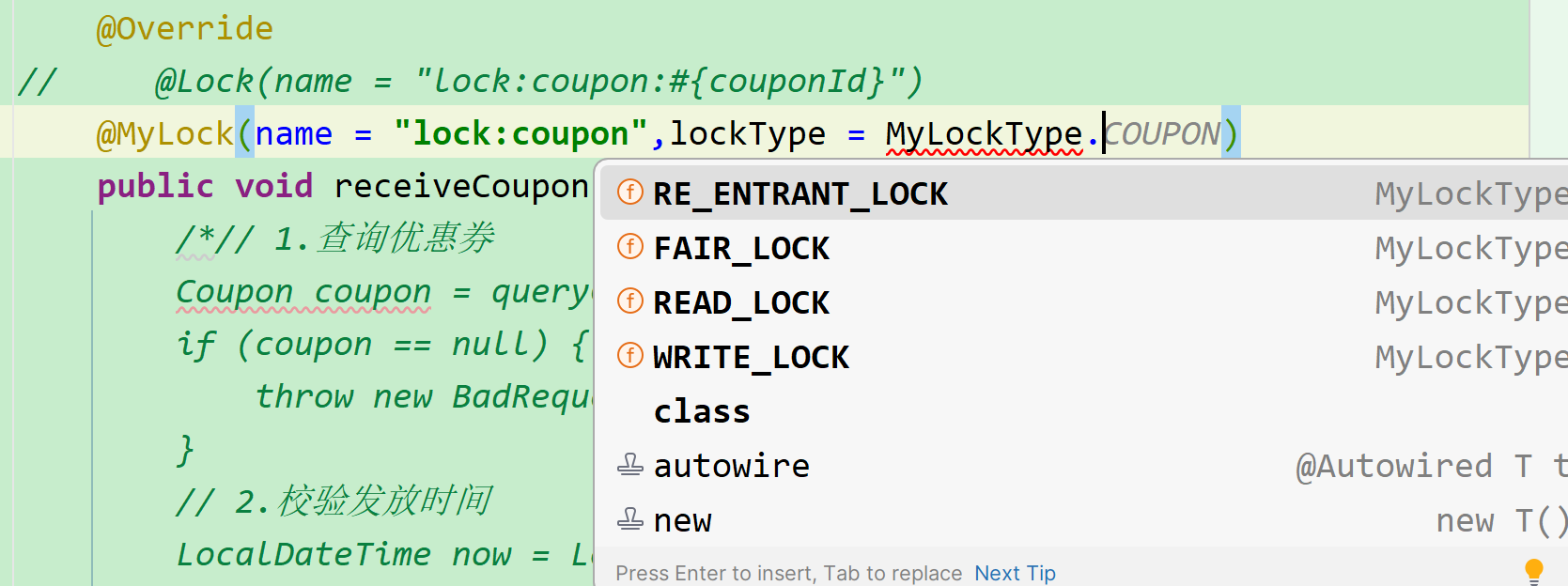
锁失败策略
多线程争抢锁,大部分线程会获取锁失败,而失败后的处理方案和策略是多种多样的。目前,我们获取锁失败后就是直接抛出异常,没有其它策略,这与实际需求不一定相符。
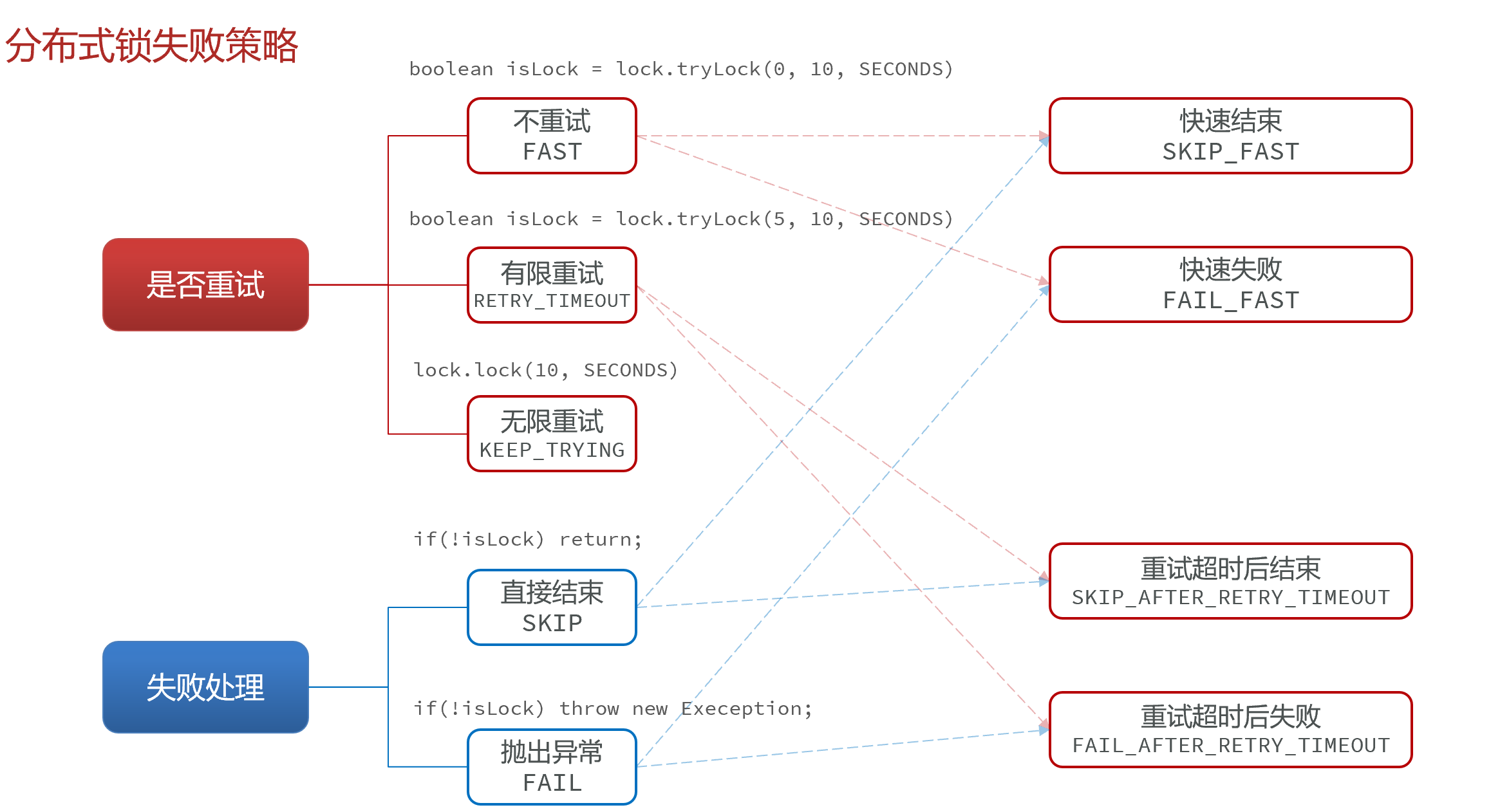
策略分析 接下来,我们就分析一下锁失败的处理策略有哪些。 大的方面来说,获取锁失败要从两方面来考虑:
- 获取锁失败是否要重试?有三种策略:
- 不重试,对应API:
lock.tryLock(0, 10, SECONDS),也就是waitTime小于等于0 - 有限次数重试:对应API:
lock.tryLock(5, 10, SECONDS),也就是waitTime大于0,重试一定waitTime时间后结束 - 无限重试:对应API
lock.lock(10, SECONDS), lock就是无限重试
- 不重试,对应API:
- 重试失败后怎么处理?有两种策略:
- 直接结束
- 抛出异常
重试策略 + 失败策略组合,总共以下几种情况:
那么该如何用代码来表示这些失败策略,并让用户自由选择呢?
相信大家应该能想到一种设计模式:策略模式。同时,我们还需要定义一个失败策略的枚举。在MyLock注解中定义这个枚举类型的参数,供用户选择。
一般的策略模式大概是这样:
- 定义策略接口
- 定义不同策略实现类
- 提供策略工厂,便于根据策略枚举获取不同策略实现
而在策略比较简单的情况下,我们完全可以用枚举代替策略工厂,简化策略模式。
失败策略定义到枚举中:
public enum MyLockStrategy {
SKIP_FAST(){
@Override
public boolean tryLock(RLock lock, MyLock prop) throws InterruptedException {
return lock.tryLock(0, prop.leaseTime(), prop.unit());
}
},
FAIL_FAST(){
@Override
public boolean tryLock(RLock lock, MyLock prop) throws InterruptedException {
boolean isLock = lock.tryLock(0, prop.leaseTime(), prop.unit());
if (!isLock) {
throw new BizIllegalException("请求太频繁");
}
return true;
}
},
KEEP_TRYING(){
@Override
public boolean tryLock(RLock lock, MyLock prop) throws InterruptedException {
lock.lock( prop.leaseTime(), prop.unit());
return true;
}
},
SKIP_AFTER_RETRY_TIMEOUT(){
@Override
public boolean tryLock(RLock lock, MyLock prop) throws InterruptedException {
return lock.tryLock(prop.waitTime(), prop.leaseTime(), prop.unit());
}
},
FAIL_AFTER_RETRY_TIMEOUT(){
@Override
public boolean tryLock(RLock lock, MyLock prop) throws InterruptedException {
boolean isLock = lock.tryLock(prop.waitTime(), prop.leaseTime(), prop.unit());
if (!isLock) {
throw new BizIllegalException("请求太频繁");
}
return true;
}
},
;
public abstract boolean tryLock(RLock lock, MyLock prop) throws InterruptedException;
}
然后,在MyLock注解中添加枚举参数
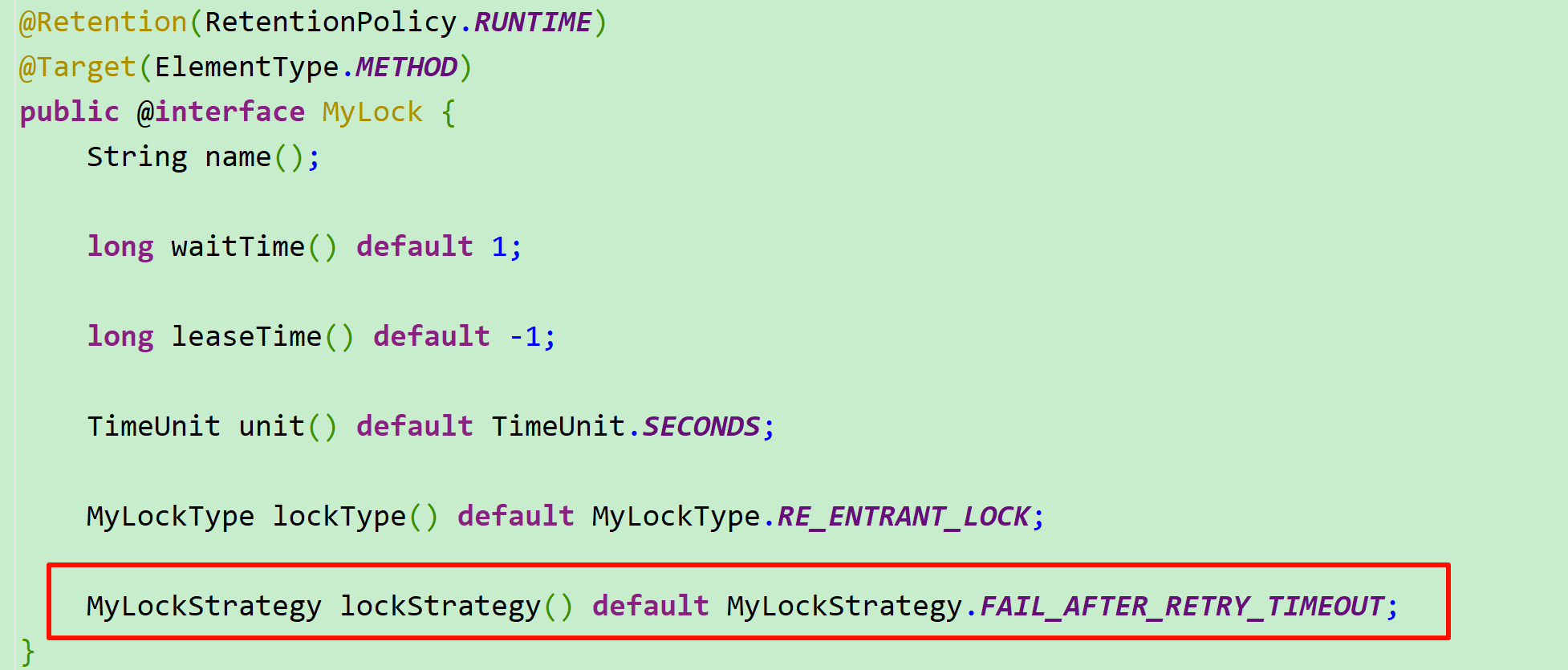
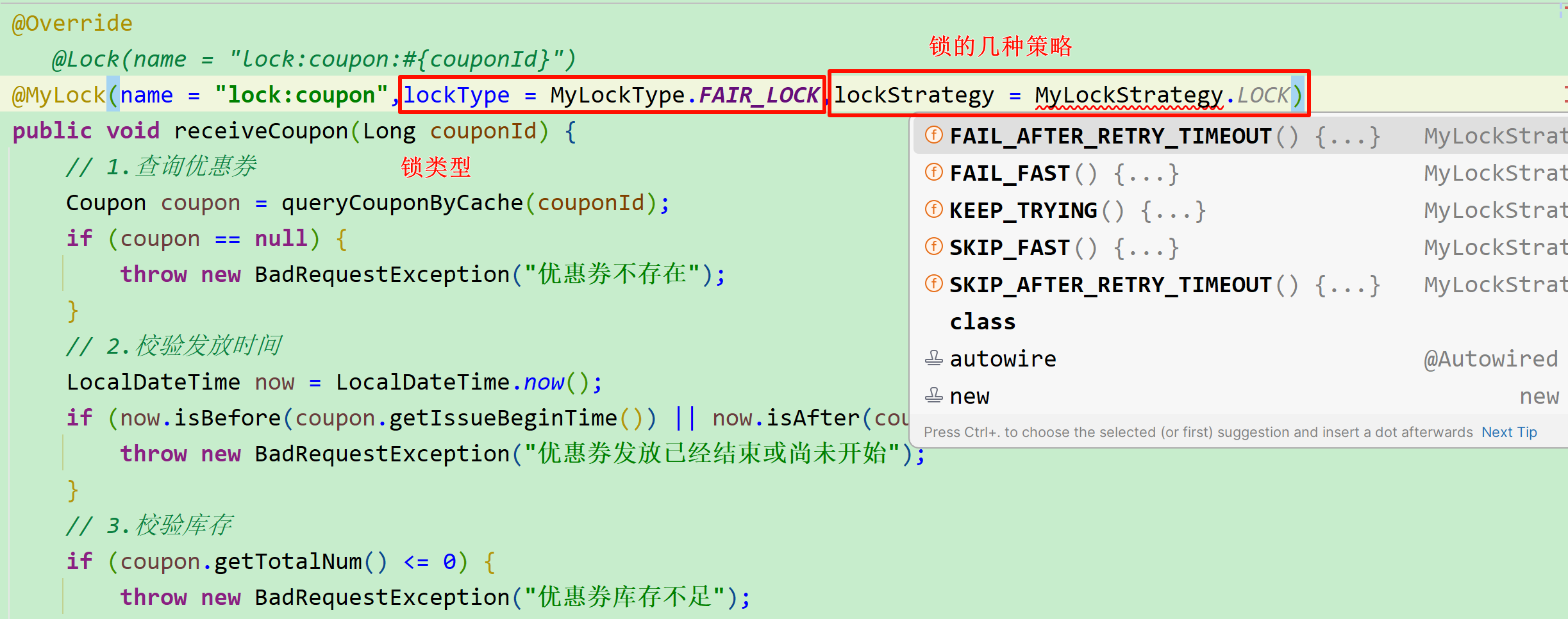
我们就可以在使用锁的时候自由选择锁类型、锁策略了
基于SPEL的动态锁名
现在还剩下最后一个问题,就是锁名称的问题。 在当前业务中,我们的锁对象本来应该是当前登录用户,是动态获取的。而加锁是基于注解参数添加的,在编码时就需要指定。怎么办?
Spring中提供了一种表达式语法,称为SPEL表达式,可以执行java代码,获取任意参数。 思路: 我们可以让用户指定锁名称参数时不要写死,而是基于SPEL表达式。在创建锁对象时,解析SPEL表达式,动态获取锁名称。
首先,在使用锁注解时,锁名称可以利用SPEL表达式,例如我们指定锁名称中要包含参数中的用户id,则可以这样写:
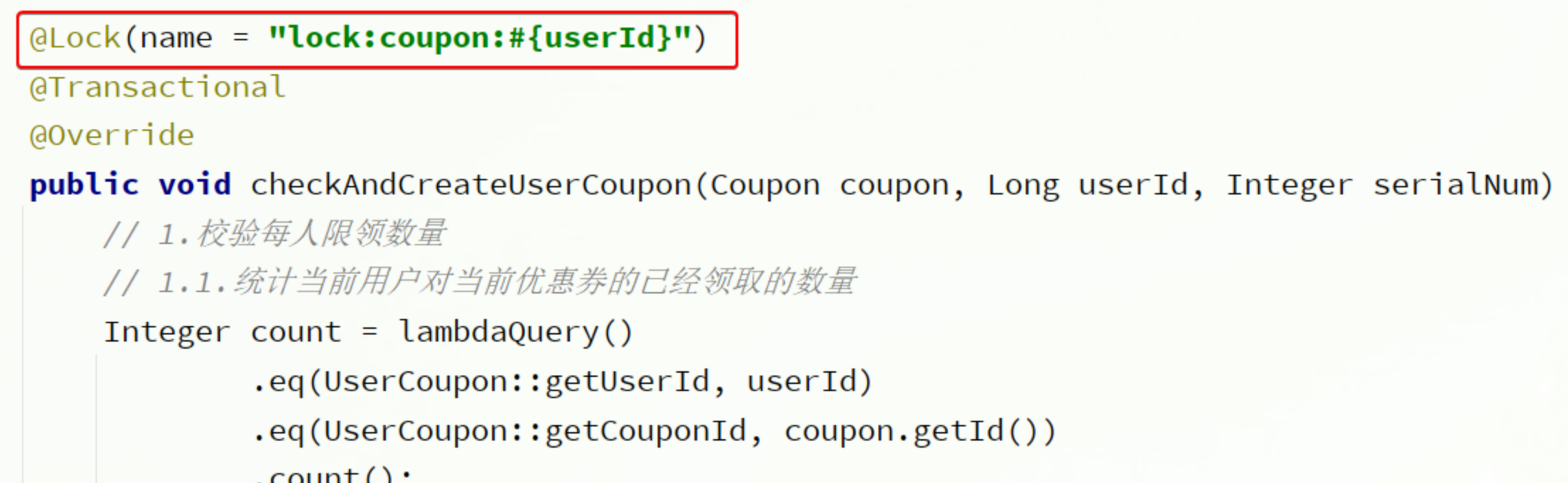 而如果是通过
而如果是通过UserContext.getUser()获取,则可以利用下面的语法:

这里T(类名).方法名()就是调用静态方法。
解析SPEL 在切面中,我们需要基于注解中的锁名称做动态解析,而不是直接使用名称:
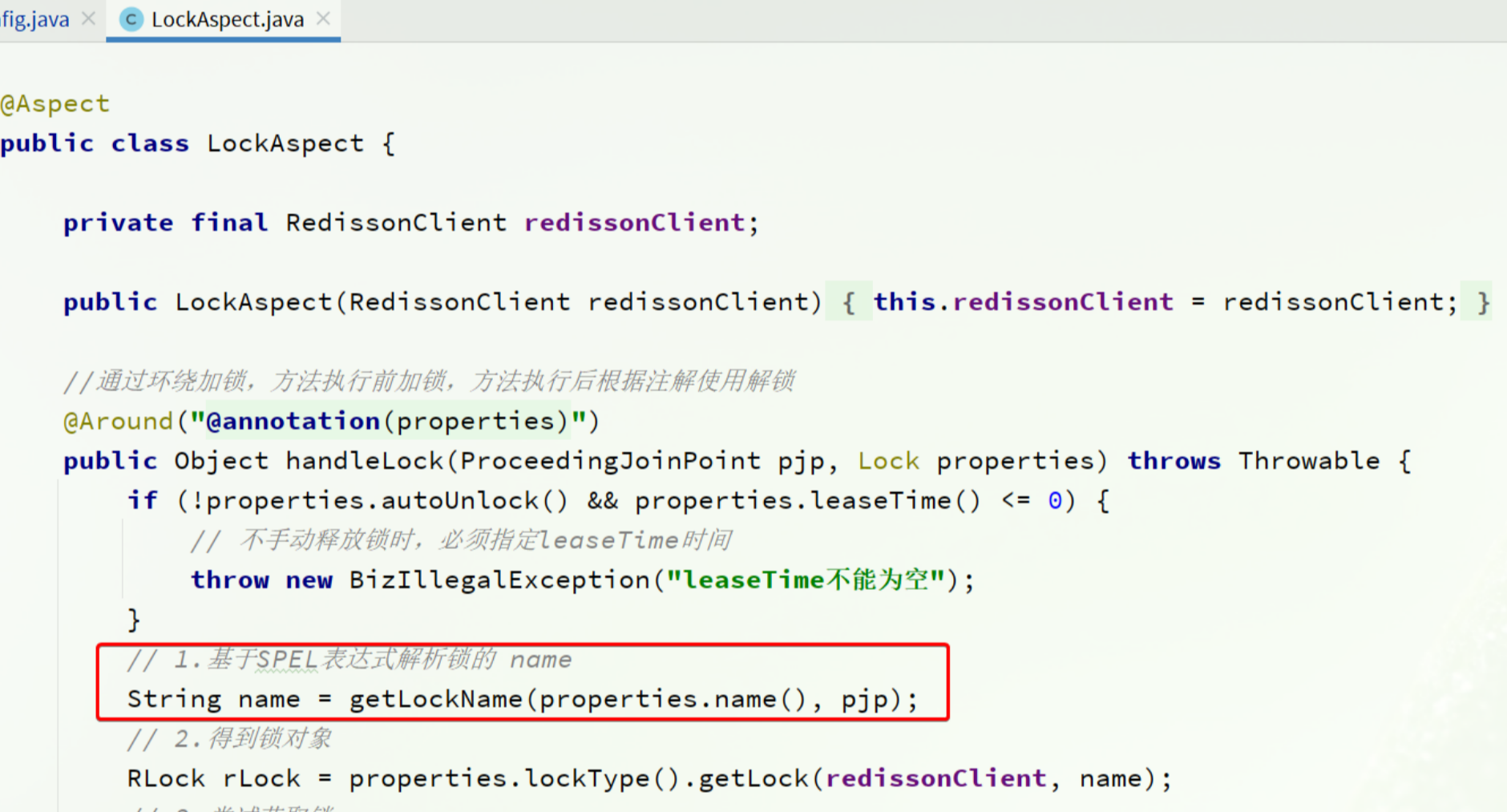
其中获取锁名称用的是getLockName()这个方法:
/**
* SPEL的正则规则
*/
private static final Pattern pattern = Pattern.compile("\\#\\{([^\\}]*)\\}");
/**
* 方法参数解析器
*/
private static final ParameterNameDiscoverer parameterNameDiscoverer = new DefaultParameterNameDiscoverer();
/**
* 解析锁名称
* @param name 原始锁名称
* @param pjp 切入点
* @return 解析后的锁名称
*/
private String getLockName(String name, ProceedingJoinPoint pjp) {
// 1.判断是否存在spel表达式
if (StringUtils.isBlank(name) || !name.contains("#")) {
// 不存在,直接返回
return name;
}
// 2.构建context,也就是SPEL表达式获取参数的上下文环境,这里上下文就是切入点的参数列表
EvaluationContext context = new MethodBasedEvaluationContext(
TypedValue.NULL, resolveMethod(pjp), pjp.getArgs(), parameterNameDiscoverer);
// 3.构建SPEL解析器
ExpressionParser parser = new SpelExpressionParser();
// 4.循环处理,因为表达式中可以包含多个表达式
Matcher matcher = pattern.matcher(name);
while (matcher.find()) {
// 4.1.获取表达式
String tmp = matcher.group();
String group = matcher.group(1);
// 4.2.这里要判断表达式是否以 T字符开头,这种属于解析静态方法,不走上下文
Expression expression = parser.parseExpression(group.charAt(0) == 'T' ? group : "#" + group);
// 4.3.解析出表达式对应的值
Object value = expression.getValue(context);
// 4.4.用值替换锁名称中的SPEL表达式
name = name.replace(tmp, ObjectUtils.nullSafeToString(value));
}
return name;
}
private Method resolveMethod(ProceedingJoinPoint pjp) {
// 1.获取方法签名
MethodSignature signature = (MethodSignature)pjp.getSignature();
// 2.获取字节码
Class<?> clazz = pjp.getTarget().getClass();
// 3.方法名称
String name = signature.getName();
// 4.方法参数列表
Class<?>[] parameterTypes = signature.getMethod().getParameterTypes();
return tryGetDeclaredMethod(clazz, name, parameterTypes);
}
private Method tryGetDeclaredMethod(Class<?> clazz, String name, Class<?> ... parameterTypes){
try {
// 5.反射获取方法
return clazz.getDeclaredMethod(name, parameterTypes);
} catch (NoSuchMethodException e) {
Class<?> superClass = clazz.getSuperclass();
if (superClass != null) {
// 尝试从父类寻找
return tryGetDeclaredMethod(superClass, name, parameterTypes);
}
}
return null;
}
领卷优化
目前我们的领取业务逻辑比较复杂,流程如图:
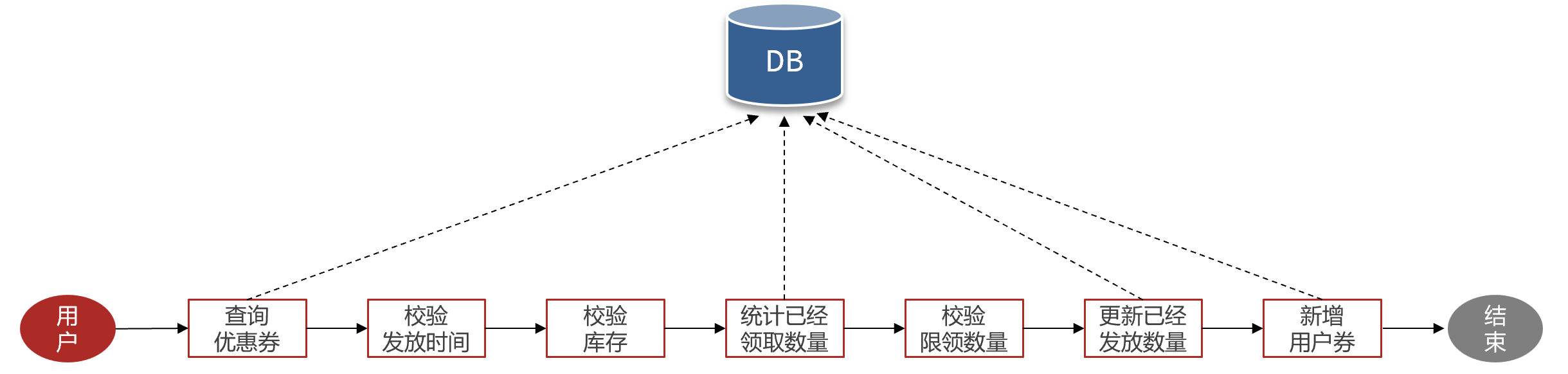
可以看到,其中有 大量的对写数据库的操作,而且过程中还加锁保证线程安全,接口串行执行导致性能有很大影响 。必须想办法提高效率。 那么对于这种高并发写业务,同时逻辑比较长且复杂的业务,该如何做优化呢?
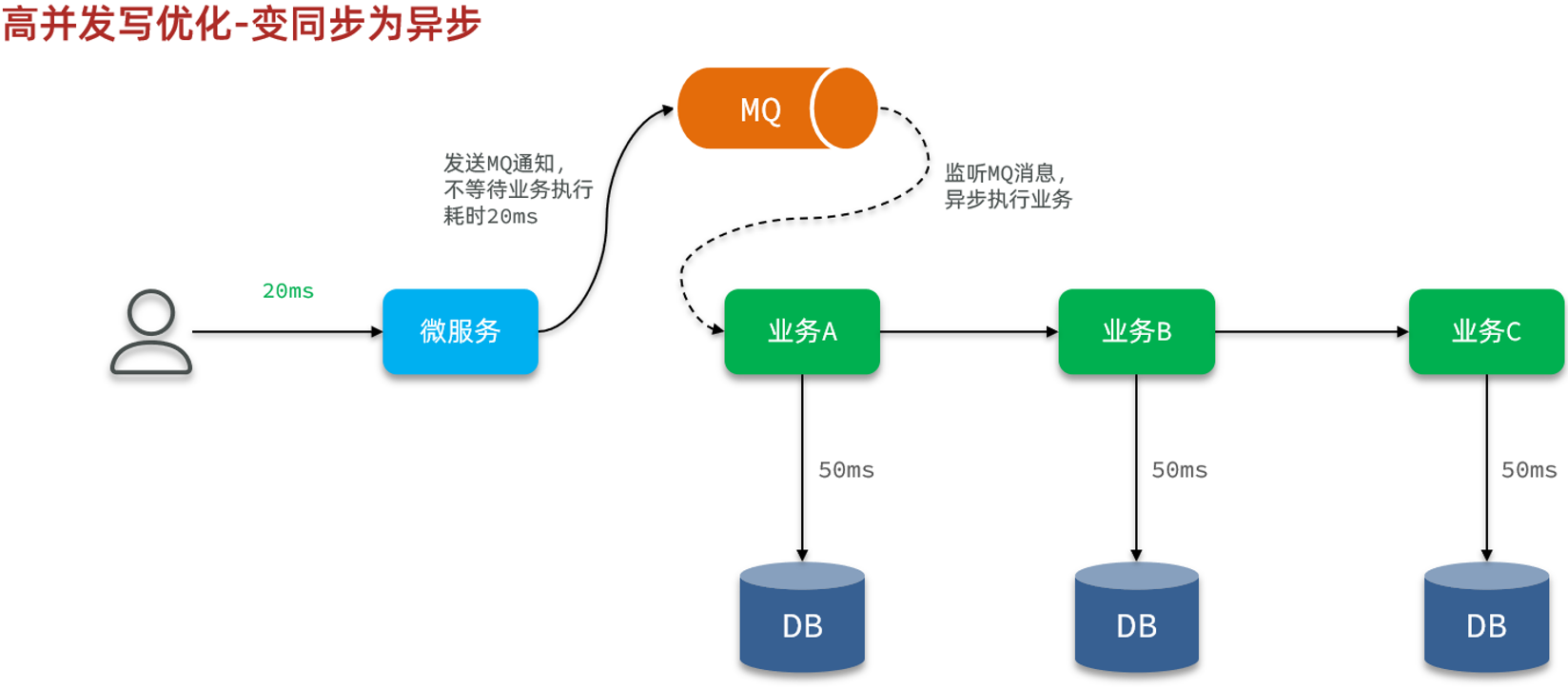
我们之前给大家分析过高并发写优化的几种思路,例如:
- 异步写:
- 合并写:
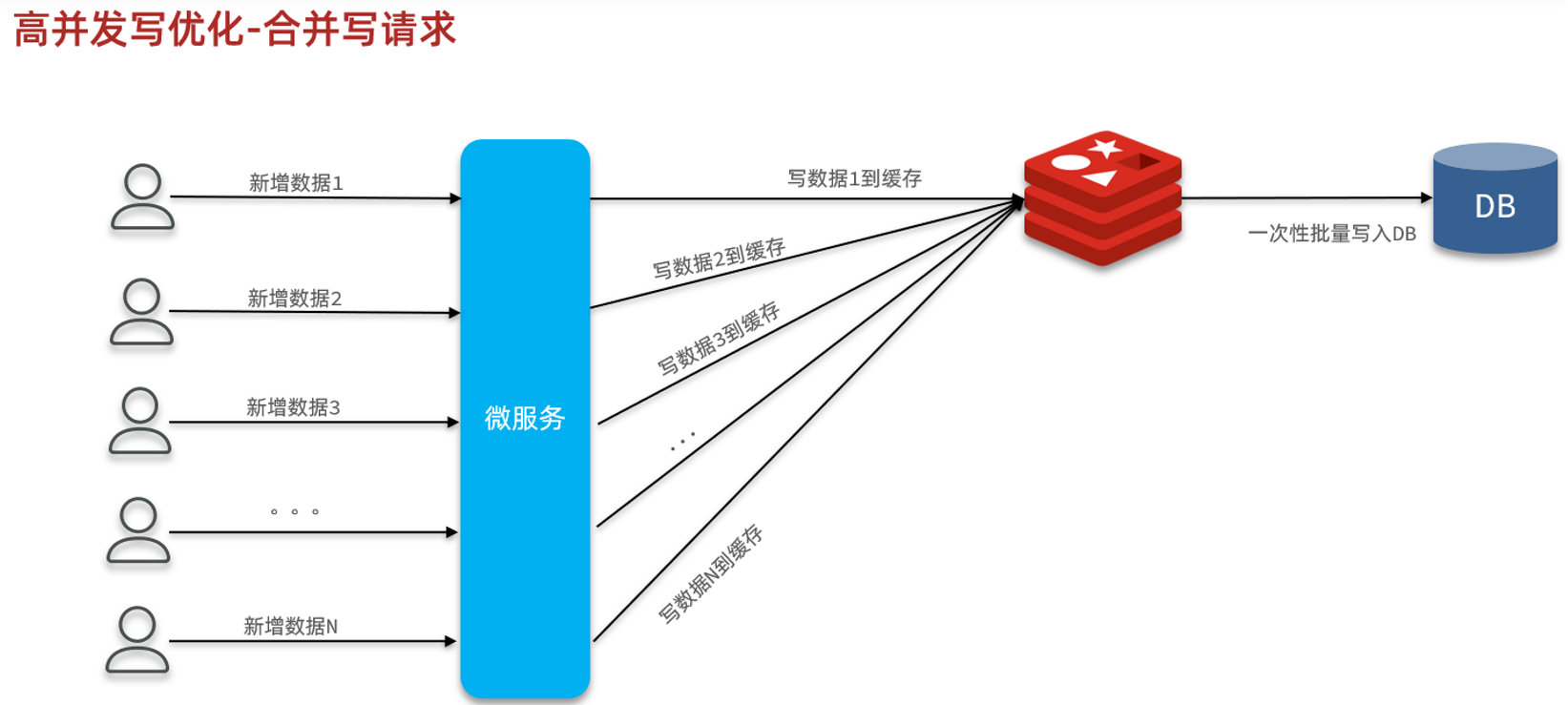
其中,合并写请求比较适合应用在写频率较高,写数据比较简单的场景。而异步写则更适合应用在业务比较复杂,业务链较长的场景。
显然,领券业务更适合使用异步写方案。
当用户请求来领券时,不是直接领券,而是通过MQ发送一个领券消息。有一个监听器监听消息,完成领券动作:
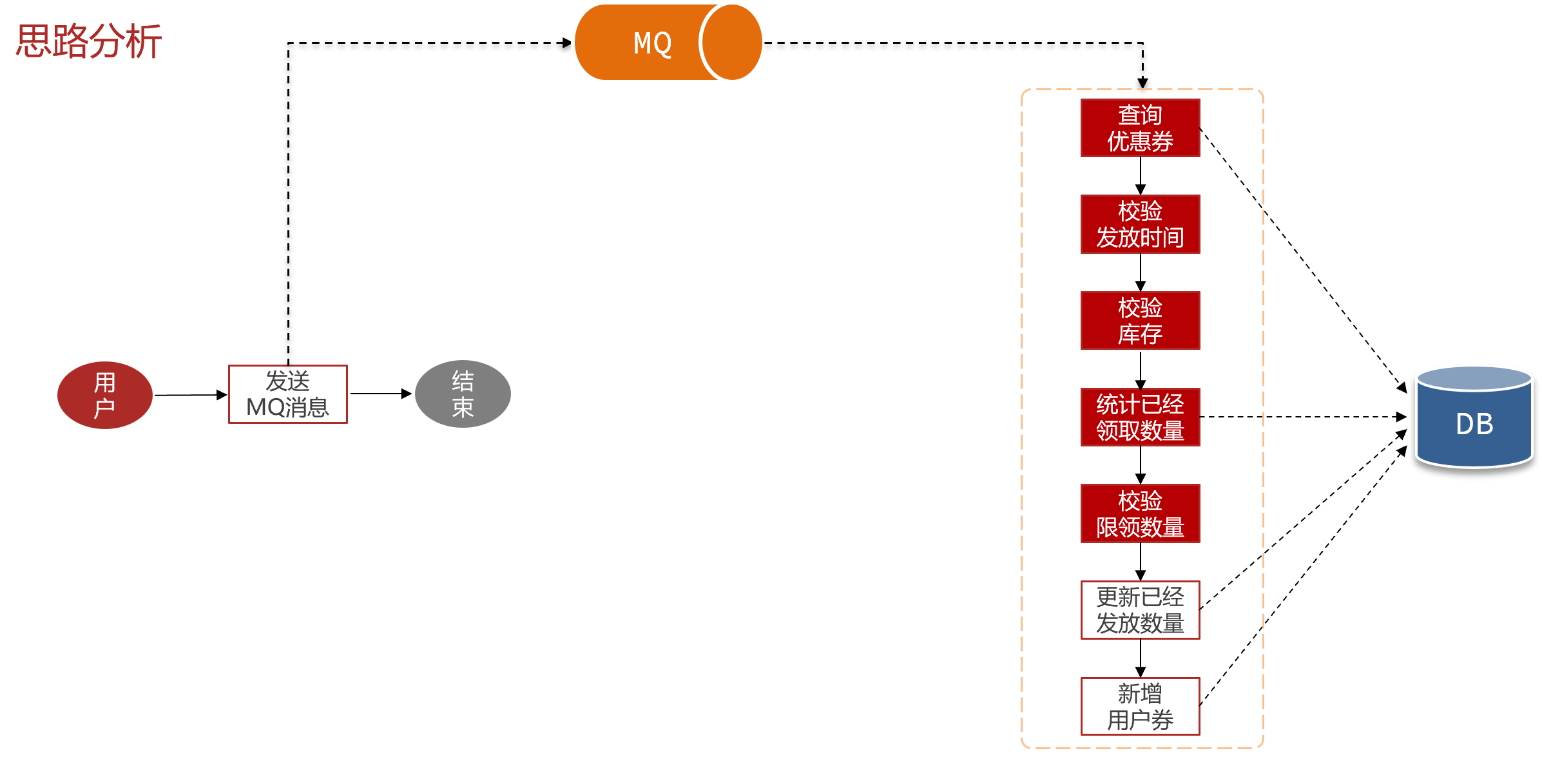
不过这里存在一个问题: 并不是每一个用户都有领券资格,具体要校验了资格才知道 。那我们在发送MQ消息后,就要返回给用户结果了,此时该告诉用户是领券成功还是失败呢? 显然,无论告诉他哪种结果都不一定正确。因此,我们应该 将校验领券资格的逻辑前置,在校验完成后再发MQ消息,完成数据库写操作 :
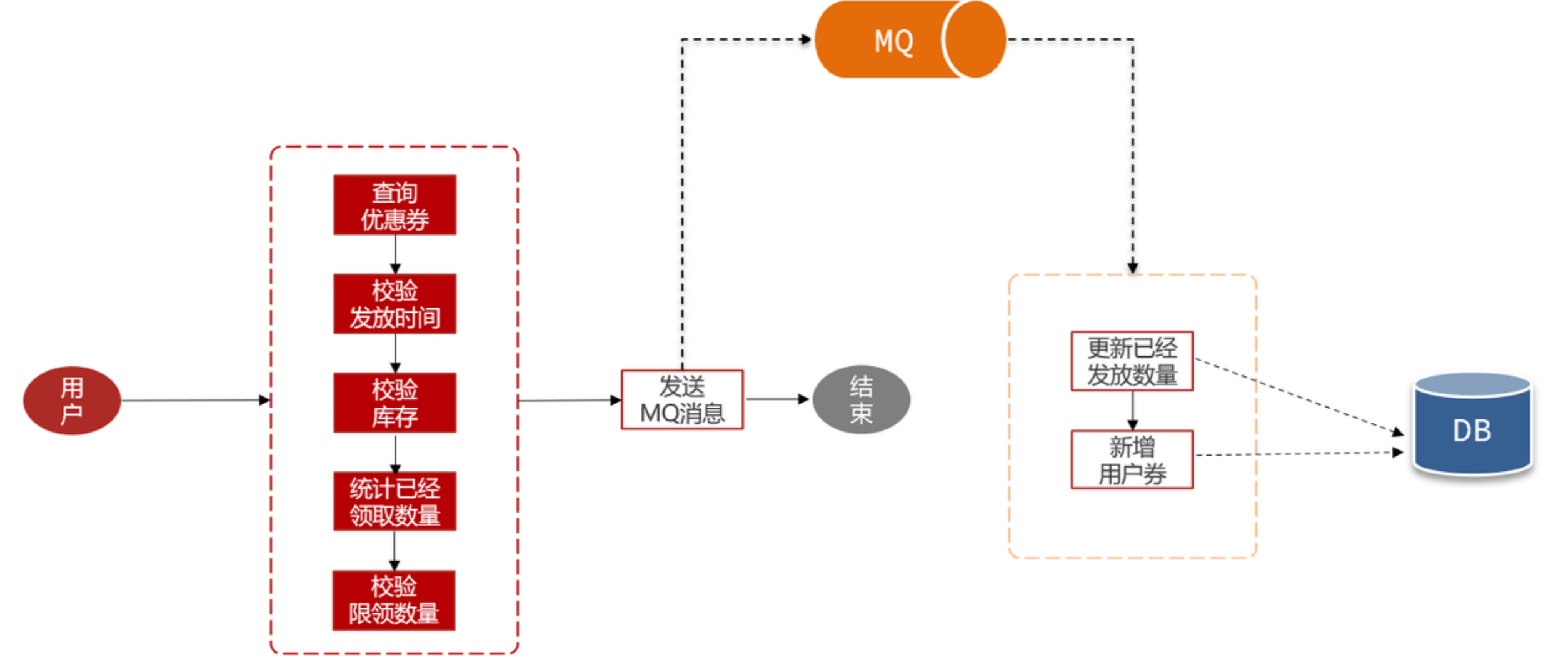
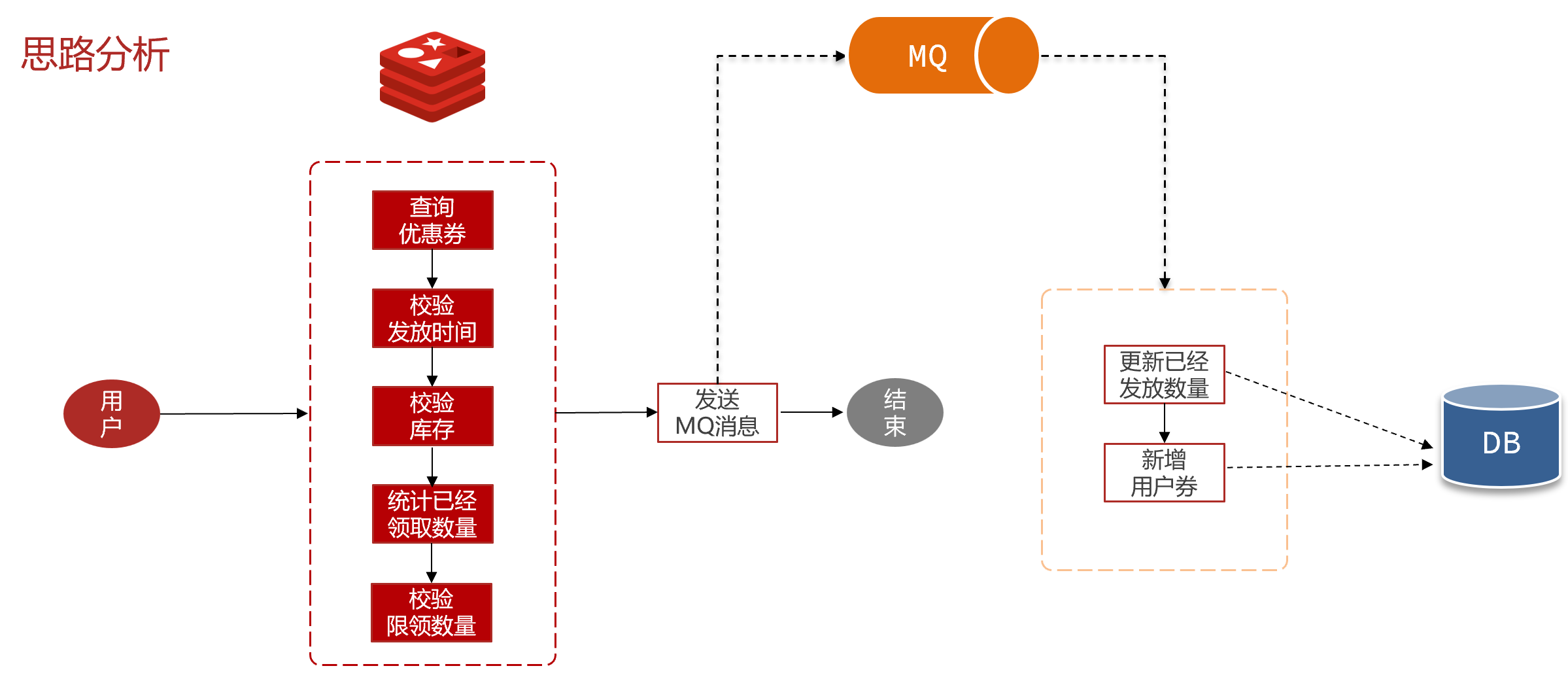
但是,校验领券资格的部分依然会有多次数据库查询,还需要加锁。效率提升并不明显,怎么办?
为了进一步提高效率,我们可以把优惠券相关数据缓存到Redis中,这样就可以基于Redis完成资格校验,不用访问数据库,效率自然会进一步提高了。
优惠券缓存数据结构
优惠券资格校验需要校验的内容包括:
- 优惠券发放时间
- 优惠券库存
- 用户限领数量
因此,为了减少对Redis内存的消耗,在构建优惠券缓存的时候,我们并不需要把所有优惠券信息写入缓存,而是只保存上述字段即可。
特别注意: 既然要在缓存中保存优惠券库存,并且校验库存是否充足。那就必须在每次校验通过后,立刻扣减Redis中缓存的库存,否则缓存中库存一直不变,起不到校验是否超发的目的。
这里我们采用Hash结构,便于我们修改缓存中的库存数据,将库存作为Hash的一个字段,将来只需要通过HINCRBY命令即可修改 ;

注意,上述结构中记录了券的每人限领数量:userLimit , 但是用户已经领取的数量并没有记录。因此,我们还 需要一个数据结构,来记录某张券,每个用户领取的数量 。
一个券可能被多个用户领取,每个用户的已领取数量都需要记录。显然,还是Hash结构更加适合:

缓存前缀:
String COUPON_CACHE_KEY_PREFIX = "prs ";
String USER_COUPON_CACHE_KEY_PREFIX = "prs
";
String USER_COUPON_CACHE_KEY_PREFIX = "prs coupon:";
coupon:";
在发放优惠券时,并且是立刻发放的优惠券,需要添加缓存。因此,我们修改发放优惠券的逻辑,代码如下:
修改原先代码:
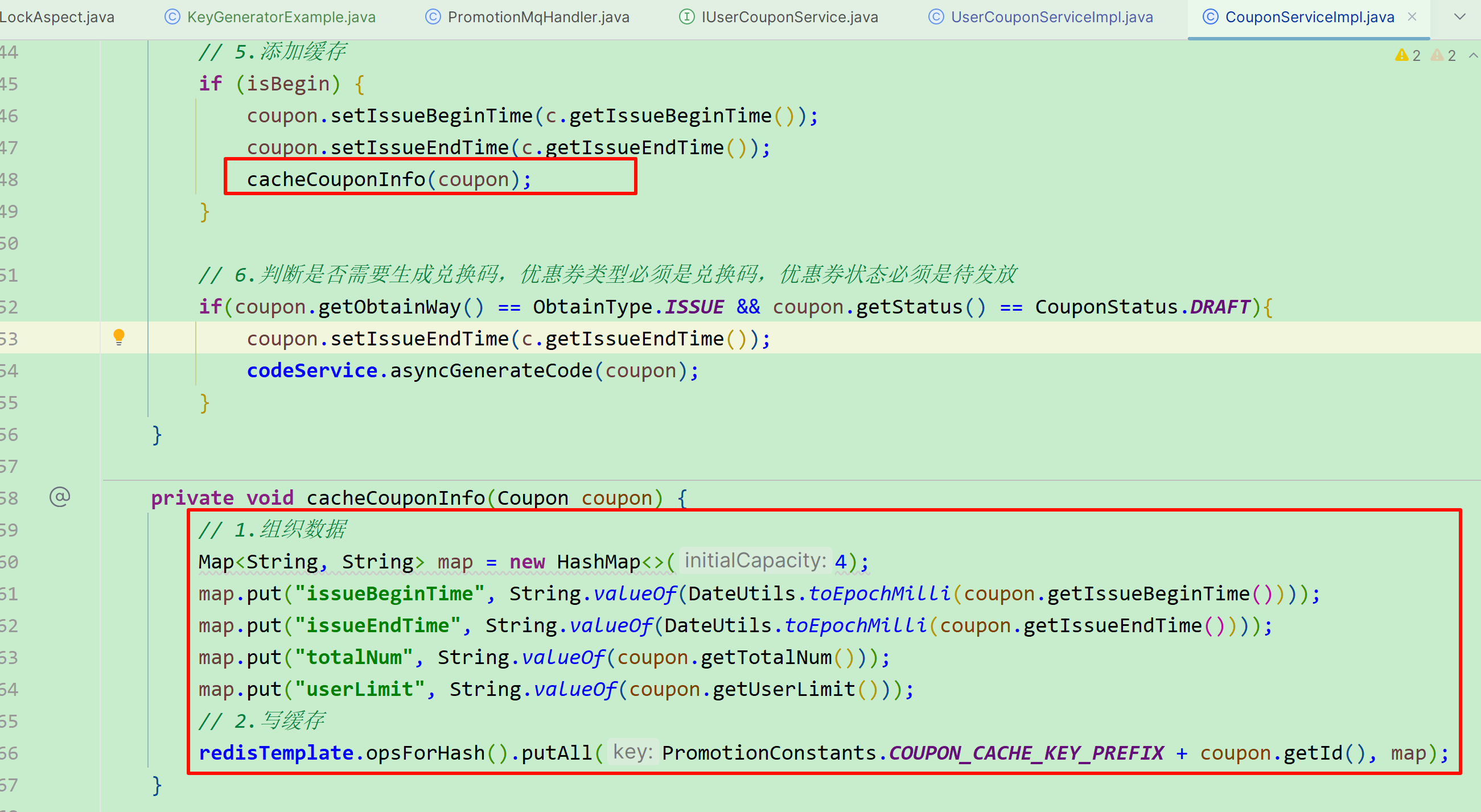
校验通过后立刻扣减redis中库存(版本一)
// 1.查询优惠券*/
Coupon coupon = queryCouponByCache(couponId);
if (coupon == null) {
throw new BadRequestException("优惠券不存在");
}
// 2.校验发放时间
LocalDateTime now = LocalDateTime.now();
if (now.isBefore(coupon.getIssueBeginTime()) || now.isAfter(coupon.getIssueEndTime())) {
throw new BadRequestException("优惠券发放已经结束或尚未开始");
}
// 3.校验库存
if (coupon.getTotalNum() <= 0) {
throw new BadRequestException("优惠券库存不足");
}
Long userId = UserContext.getUser();
// 4.校验每人限领数量
// 4.1.查询领取数量
String key = PromotionConstants.USER_COUPON_CACHE_KEY_PREFIX + couponId;
Long count = redisTemplate.opsForHash().increment(key, userId.toString(), 1);
// 4.2.校验限领数量
if(count > coupon.getUserLimit()){
throw new BadRequestException("超出领取数量");
}
// 5.扣减优惠券库存
redisTemplate.opsForHash().increment(
PromotionConstants.COUPON_CACHE_KEY_PREFIX + couponId, "totalNum", -1);
校验通过后立刻扣减redis中库存(版本二:LUA脚本)
// 1.执行LUA脚本,判断结果
// 1.1.准备参数
String key1 = PromotionConstants.COUPON_CACHE_KEY_PREFIX + couponId;
String key2 = PromotionConstants.USER_COUPON_CACHE_KEY_PREFIX + couponId;
Long userId = UserContext.getUser();
// 1.2.执行脚本
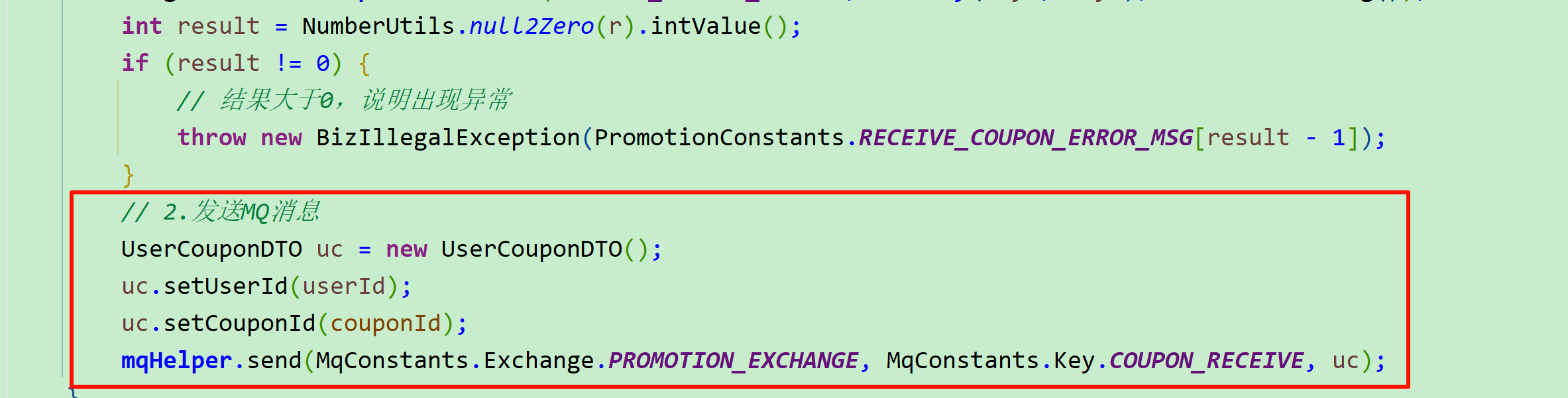
Long r = redisTemplate.execute(RECEIVE_COUPON_SCRIPT, List.of(key1, key2), userId.toString());
int result = NumberUtils.null2Zero(r).intValue();
if (result != 0) {
// 结果大于0,说明出现异常
throw new BizIllegalException(PromotionConstants.RECEIVE_COUPON_ERROR_MSG[result - 1]);
}
LUA解本
if(redis.call('exists', KEYS[1]) == 0) then
return 1
end
if(tonumber(redis.call('hget', KEYS[1], 'totalNum')) <= 0) then
return 2
end
if(tonumber(redis.call('time')[1]) > tonumber(redis.call('hget', KEYS[1], 'issueEndTime'))) then
return 3
end
if(tonumber(redis.call('hget', KEYS[1], 'userLimit')) < redis.call('hincrby', KEYS[2], ARGV[1], 1)) then
return 4
end
redis.call('hincrby', KEYS[1], "totalNum", "-1")
return 0
异步领券
接下来我们就可以开始实现异步领券了。分为两步:
- 改造领券逻辑,实现 基于Redis的领取资格校验,然后发送MQ消息
- 编写MQ监听器,监听到消息后执行领券逻辑
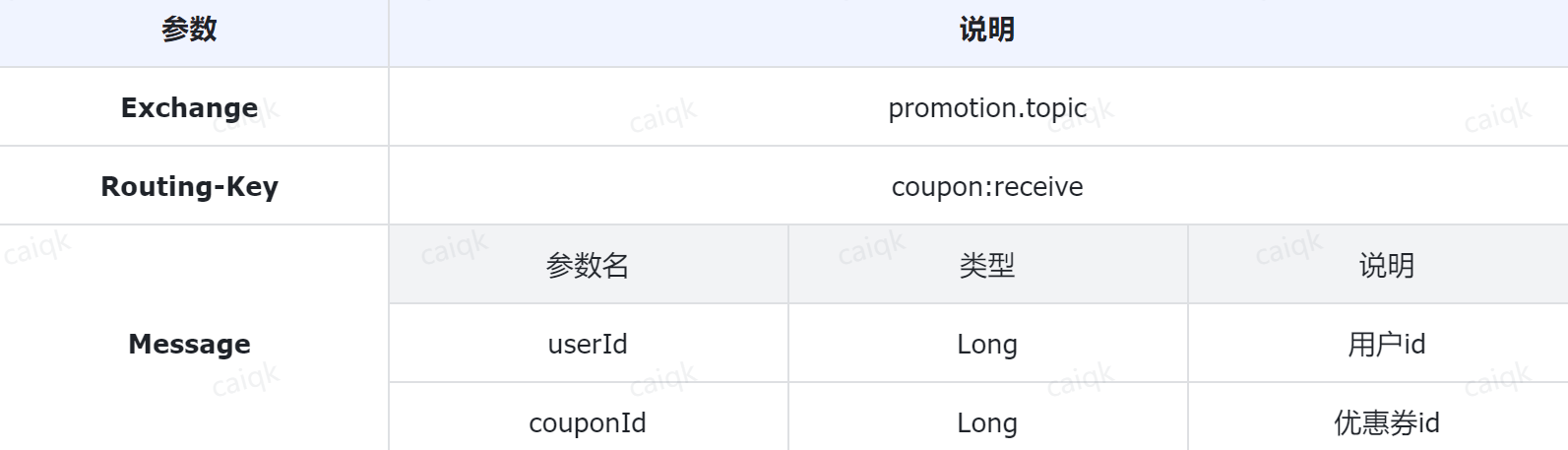
定义MQ消息规范 首先,我们定义一下MQ消息通信的规范。来回顾一下异步领券的流程:
在发送MQ消息之前已经完成了领券资格校验,因此监听到MQ消息时只需要做两件事情:
- 更新券的已发放数量
- 新增用户券
更新券已发放数量只需要知道券id(couponId)即可,而新增用户券则需要知道用户信息(userId),因此我们发送的MQ消息中只要包含这两个字段即可。
对原先代码经行改造
消息监听器
@RequiredArgsConstructor
@Component
public class PromotionMqHandler {
private final IUserCouponService userCouponService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "coupon.receive.queue", durable = "true"),
exchange = @Exchange(name = PROMOTION_EXCHANGE, type = ExchangeTypes.TOPIC),
key = COUPON_RECEIVE
))
public void listenCouponReceiveMessage(UserCouponDTO uc){
userCouponService.checkAndCreateUserCoupon(uc);
}
}
UserCouponServiceImpl#checkAndCreateUserCoupon
@Transactional
@Override
public void checkAndCreateUserCoupon(UserCouponDTO uc) {
// 1.查询优惠券
Coupon coupon = couponMapper.selectById(uc.getCouponId());
if (coupon == null) {
throw new BizIllegalException("优惠券不存在!");
}
// 2.更新优惠券的已经发放的数量 + 1
int r = couponMapper.incrIssueNum(coupon.getId());
if (r == 0) {
throw new BizIllegalException("优惠券库存不足!");
}
// 3.新增一个用户券
saveUserCoupon(coupon, uc.getUserId());
// 4.更新兑换码状态
if (uc.getSerialNum() != null) {
codeService.lambdaUpdate()
.set(ExchangeCode::getUserId, uc.getUserId())
.set(ExchangeCode::getStatus, ExchangeCodeStatus.USED)
.eq(ExchangeCode::getId, uc.getSerialNum())
.update();
}
}
总结
模拟面试 你做的优惠券功能如何解决券超发的问题?
券超发问题常见的有两种场景:
- 券库存不足导致超发
- 发券时超过了每个用户限领数量
这两种问题产生的原因都是高并发下的线程安全问题。往往需要通过加锁来保证线程安全。不过在处理细节上,会有一些差别。
首先,针对库存不足导致的超发问题,也就是典型的库存超卖问题,我们可以通过乐观锁来解决。也就是在库存扣减的SQL语句中添加对于库存余量的判断。当然这里不必要求必须与查询到的库存一致,因为这样可能导致库存扣减失败率太高。而是判断库存是否大于0即可,这样既保证了安全,也提高了库存扣减的成功率。
其次,对于用户限领数量超出的问题,我们无法采用乐观锁。因为要判断是否超发,需要先查询用户已领取数量,然后判断有没有超过限领数量,没有超过才会新增一条领取记录。这就导致后续的新增操作会影响超发的判断,只能利用悲观锁将查询已领数量、判断超发、新增领取记录几个操作封装为原子操作。这样才能保证线程的安全。
那你这里聊到悲观锁,是用什么来实现的呢?
由于在我们项目中,优惠券服务是多实例部署形成的负载均衡集群。因此考虑到分布式下JVM锁失效问题,我们采用了基于Redisson的分布式锁。
(此处面试官可能会追问怎么实现的呢?如果没有追问就自己往下说,不要停)
不过Redisson分布式锁的加锁和释放锁逻辑对业务侵入比较多,因此我就对其做了二次封装(强调是自己做的),利用自定义注解,AOP,以及SPEL表达式实现了基于注解的分布式锁。(面试官可能会问SPEL用来做什么,没问的话就自己说)
我在封装的时候用了工厂模式来选择不同的锁类型,利用了策略模式来选择锁失败重试策略,利用SPEL表达式来实现动态锁名称。
(面试官可能追问锁失败重试的具体策略,没有就自己往下说)
因为获取锁可能会失败嘛,失败后可以重试,也可以不重试。如果重试结束可以直接报错,也可以快速结束。综合来说可能包含5种不同失败重试策略。例如:失败后直接结束、失败后直接抛异常、失败后重试一段时间然后结束、失败后重试一段时间然后抛异常、失败后一直重试。
加锁以后性能会比较差,有什么好的办法吗?
解决性能问题的办法有很多,针对领券问题,我们可以采用MQ来做异步领券,起到一个流量削峰和整型的作用,降低数据库压力。
具体来说,我们可以将优惠券的关键信息缓存到Redis中,用户请求进入后先读取Redis缓存,做好优惠券库存、领取数量的校验,如果校验不通过直接返回失败结果。如果校验通过则通过MQ发送消息,异步去写数据库,然后告诉用户领取成功即可。
当然,前面说的这种办法也存在一个问题,就是可能需要多次与Redis交互。因此还有一种思路就是利用Redis的LUA脚本来编写校验逻辑来代替java编写的校验逻辑。这样就只需要向Redis发一次请求即可完成校验。






评论( 0 )