分布式任务调度原理
那么分布式任务调度是如何实现任务调度和编排的呢? 我们先来看看普通定时任务的实现原理,一般定时任务中会有两个组件:
- 任务:要执行的代码
- 任务触发器:基于定义好的规则触发任务
因此在多实例部署的时候,每个启动的服务实例都会有自己的任务触发器,这样就会导致各个实例各自运行,无法统一控制:
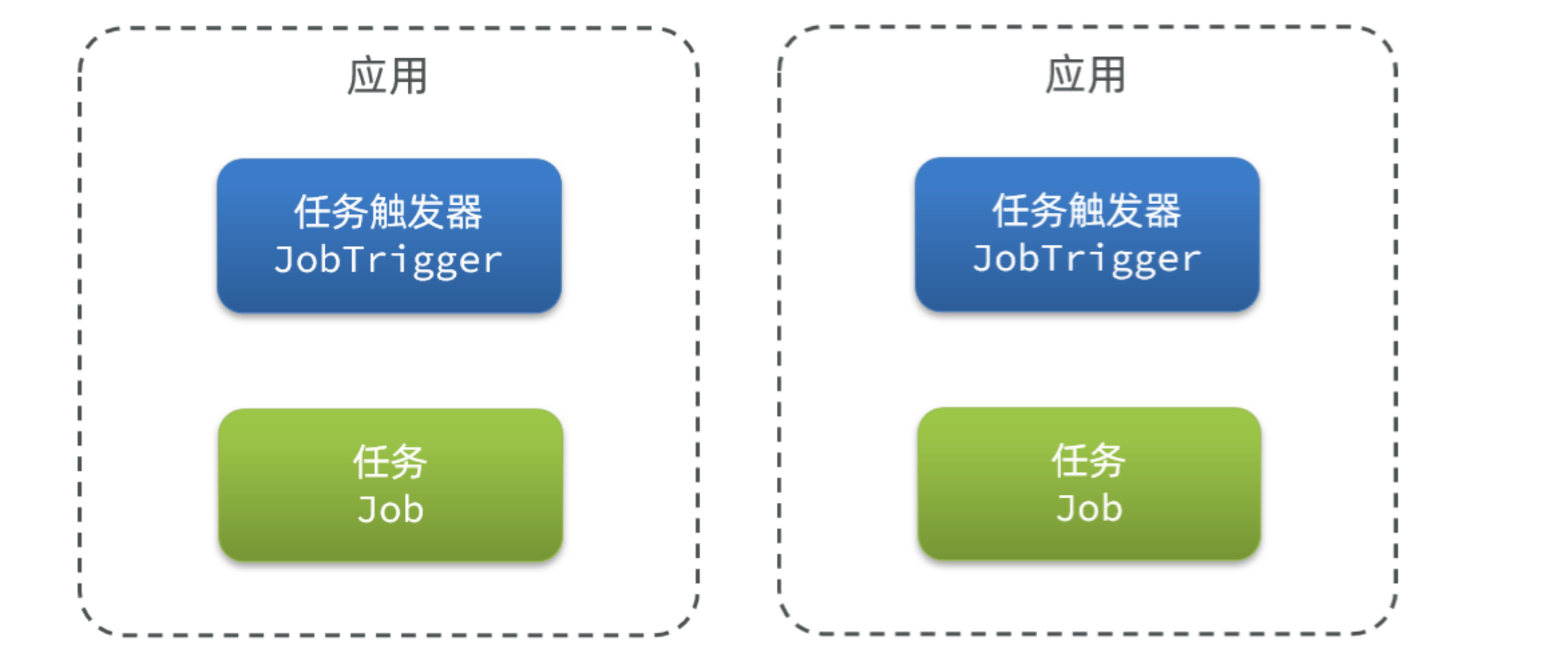
那如果我们想要统一控制各个服务实例的任务执行和调度该怎么办?
大家应该能想到:就是要把 任务触发器提取到各个服务实例之外,去做统一的触发、统一的调度。 事实上,大多数的分布式任务调度组件都是这样做的:
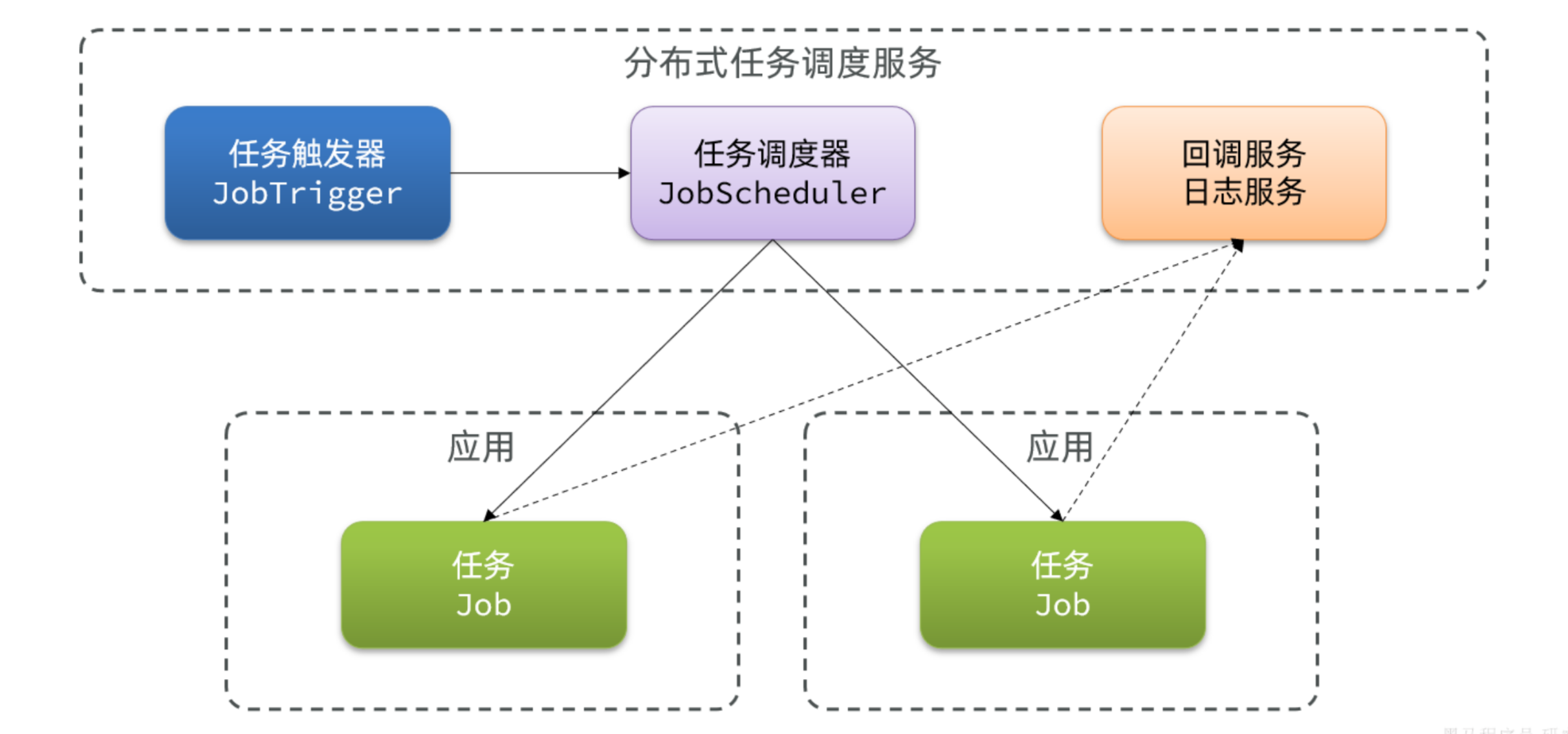
这样一来,具体哪个任务该执行,什么时候执行,交给哪个应用实例来执行,全部都有统一的任务调度服务来统一控制。并且执行过程中的任务结果还可以通过 回调接口返回,让我们方便的查看任务执行状态、执行日志。这样的服务就是分布式调度服务了。
分布式任务调度技术对比
能够实现分布式任务调度的技术有很多,常见的有:
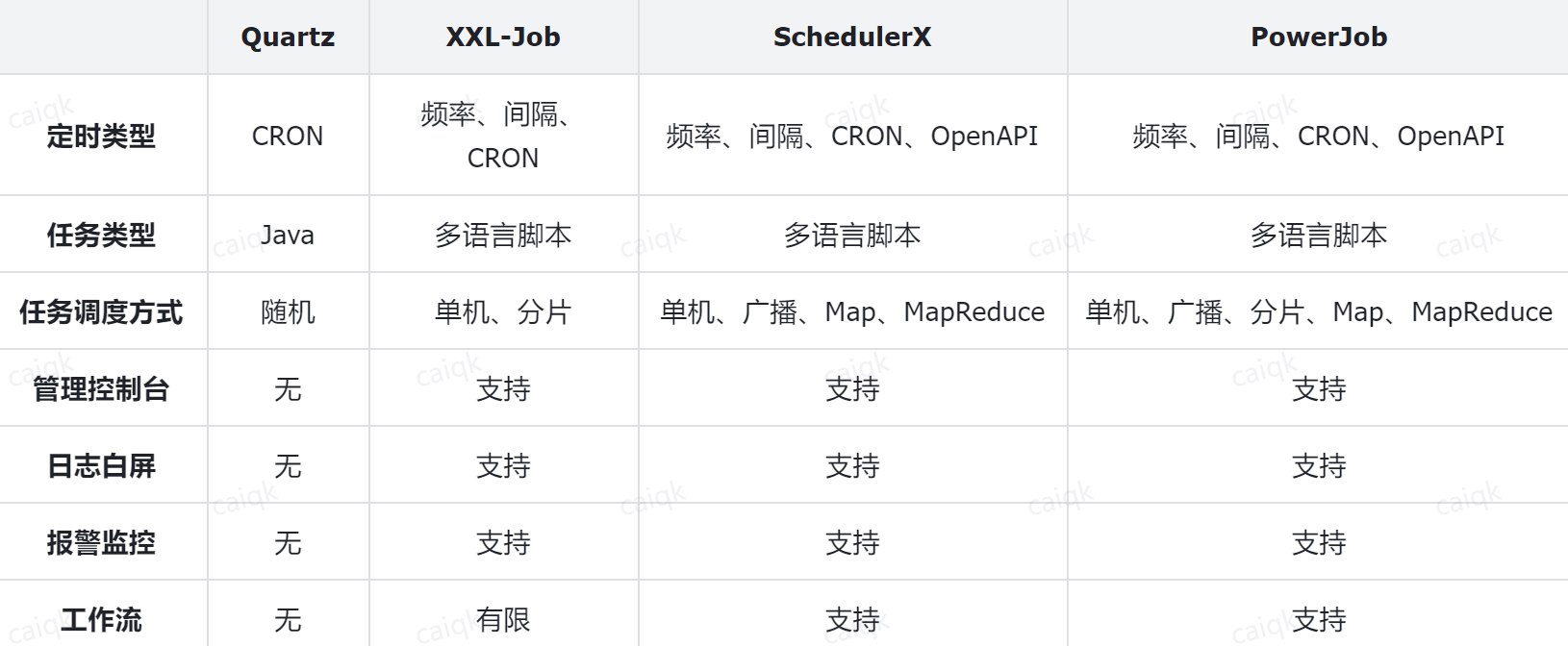
其中:
- Quartz由于功能相对比较落后,现在已经很少被使用了。
- SchedulerX是阿里巴巴的云产品,收费。
- PowerJob是阿里员工自己开源的一个组件,功能非常强大,不过目前市值占比还不高,还需要等待市场检验。
- XXL-JOB:开源免费,功能虽然不如PowerJob,不过目前市场占比最高,稳定性有保证。
我们会选择XXL-JOB这个组件,如果你们企业具备探索精神,而且需要一些分布式运算功能,推荐使用PowerJob。
XXL-JOB介绍
XXL-JOB的运行原理和架构如图:
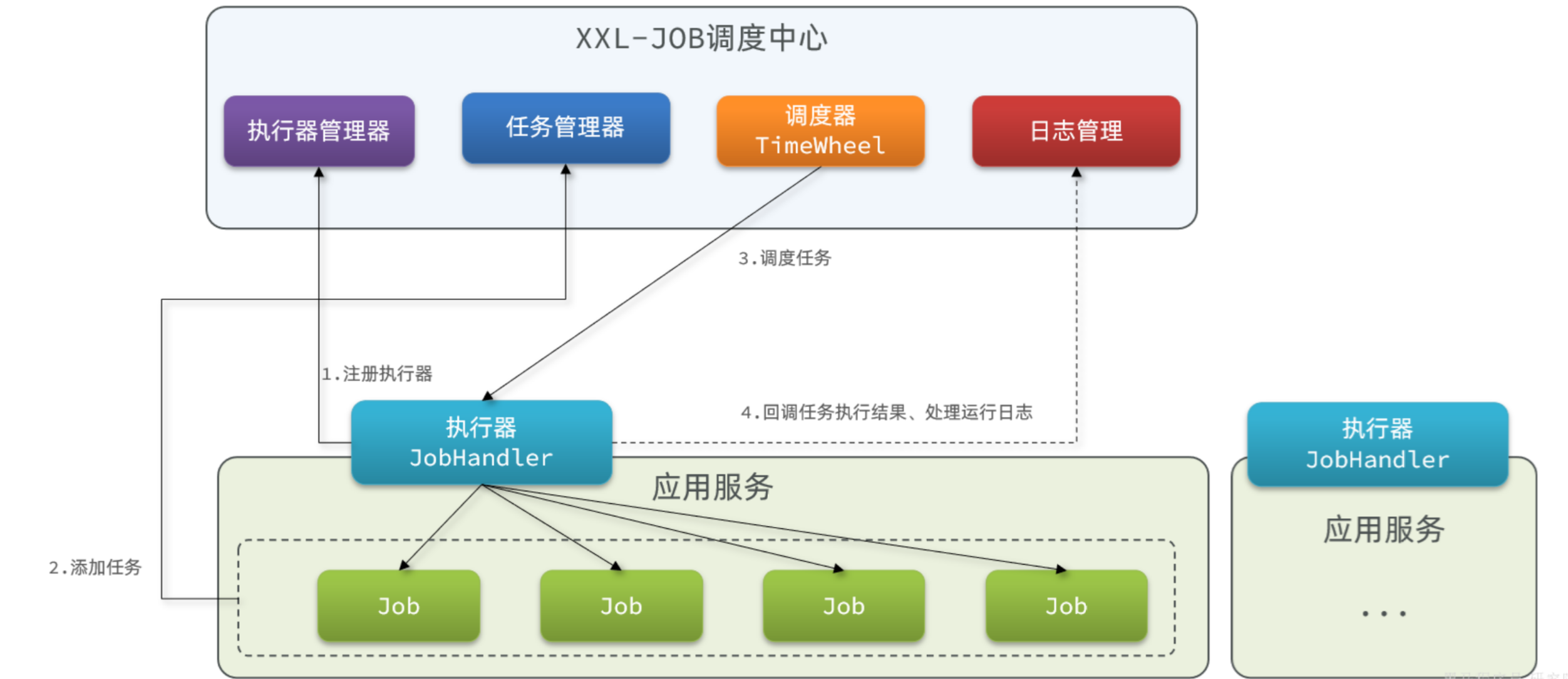
XXL-JOB分为两部分:
- 执行器:我们的服务引入一个XXL-JOB的依赖,就可以通过配置创建一个执行器。负责与XXL-JOB调度中心交互,执行本地任务。
- 调度中心:一个独立服务,负责 管理执行器、管理任务、任务执行的调度、任务结果和日志收集 。
在我们项目中
对xxl-job相关的定时任务执行情况建立了几张表来记录日志操作

- xxl_job_lock: 任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的
扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等; - xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的
历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等; - xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务
GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能; - xxl_job_registry:执行器注册表,
维护在线的执行器和调度中心机器地址信息; - xxl_job_user:系统用户表;
微服务集成执行器
首先需要在tj-learning服务引入依赖:
<!--xxl-job-->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>
然后还需要配置执行器,下面是一个配置执行器的示例:
@Data
@ConfigurationProperties(prefix = "tj.xxl-job")
public class XxlJobProperties {
private String accessToken;
private Admin admin;
private Executor executor;
@Data
public static class Admin {
private String address;
}
@Data
public static class Executor {
private String appName;
private String address;
private String ip;
private Integer port;
private String logPath;
private Integer logRetentionDays;
}
}
@Slf4j
@Configuration
@ConditionalOnClass(XxlJobSpringExecutor.class)
@EnableConfigurationProperties(XxlJobProperties.class)
public class XxlJobConfig {
@Bean
public XxlJobSpringExecutor xxlJobExecutor(XxlJobProperties prop) {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
XxlJobProperties.Admin admin = prop.getAdmin();
if (admin != null && StringUtils.isNotEmpty(admin.getAddress())) {
xxlJobSpringExecutor.setAdminAddresses(admin.getAddress());
}
XxlJobProperties.Executor executor = prop.getExecutor();
if (executor != null) {
if (executor.getAppName() != null)
xxlJobSpringExecutor.setAppname(executor.getAppName());
if (executor.getIp() != null)
xxlJobSpringExecutor.setIp(executor.getIp());
if (executor.getPort() != null)
xxlJobSpringExecutor.setPort(executor.getPort());
if (executor.getLogPath() != null)
xxlJobSpringExecutor.setLogPath(executor.getLogPath());
if (executor.getLogRetentionDays() != null)
xxlJobSpringExecutor.setLogRetentionDays(executor.getLogRetentionDays());
}
if (prop.getAccessToken() != null)
xxlJobSpringExecutor.setAccessToken(prop.getAccessToken());
log.info(">>>>>>>>>>> xxl-job config end.");
return xxlJobSpringExecutor;
}
}
参数说明:
- adminAddress:
调度中心地址,项目中就是填虚拟机地址 - appname:
微服务名称 - ip和port:当前执行器的ip和端口,无需配置,自动获取
- accessToken:访问令牌,在调度中心中配置令牌,所有执行器访问时都必须携带该令牌,否则无法访问。咱们项目的令牌已经配好,就是tianji。如果要修改,可以到虚拟机的/usr/local/src/xxl-job/application.properties文件中,修改xxl.job.accessToken属性,然后重启XXL-JOB即可。
- logPath:任务运行日志的保存目录
- logRetentionDays:日志最长保留时长
配置中的关键属性都已经在Nacos中共享了
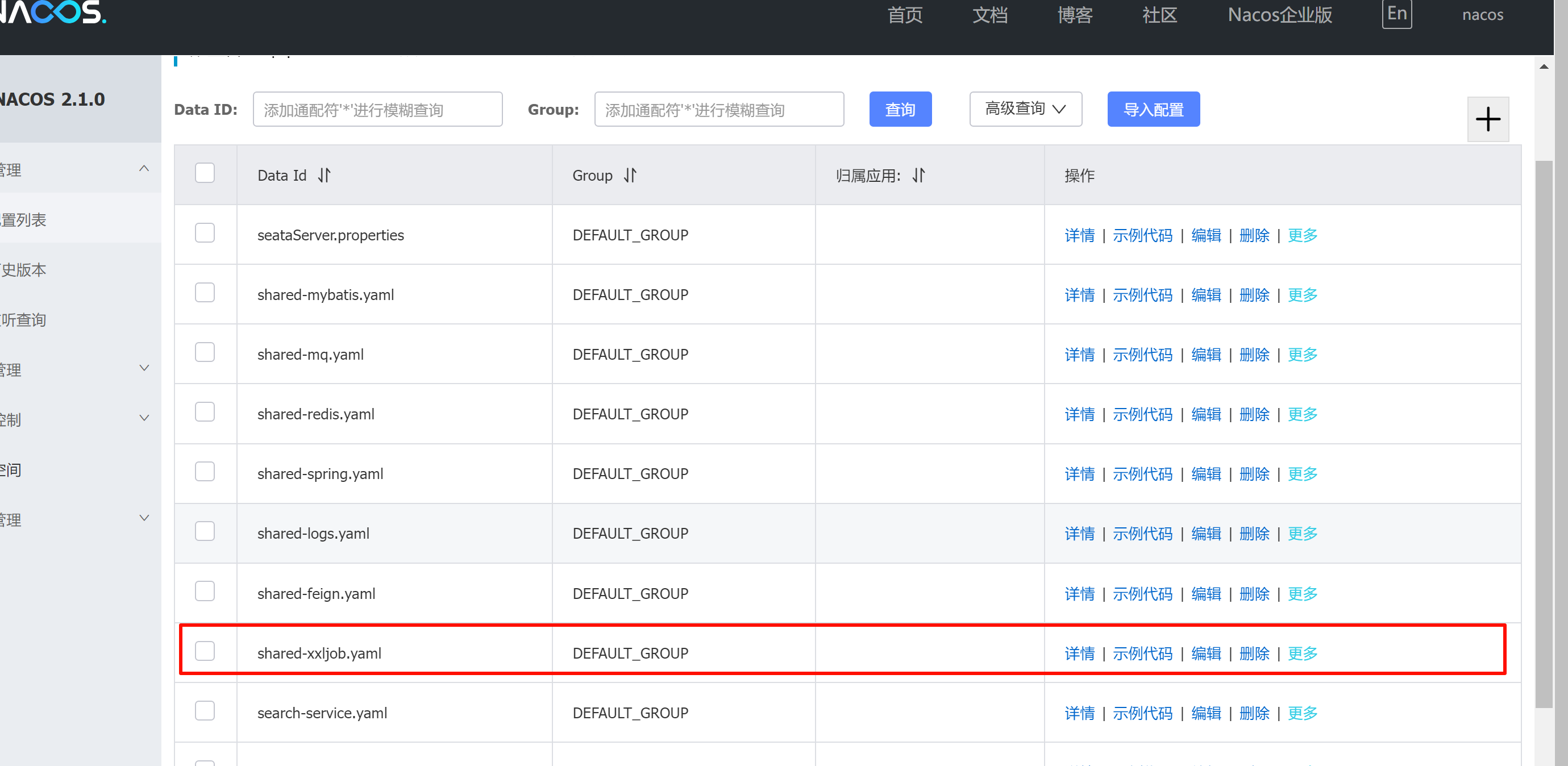
代码中@XxlJob注解中定义的就是当前任务的名称
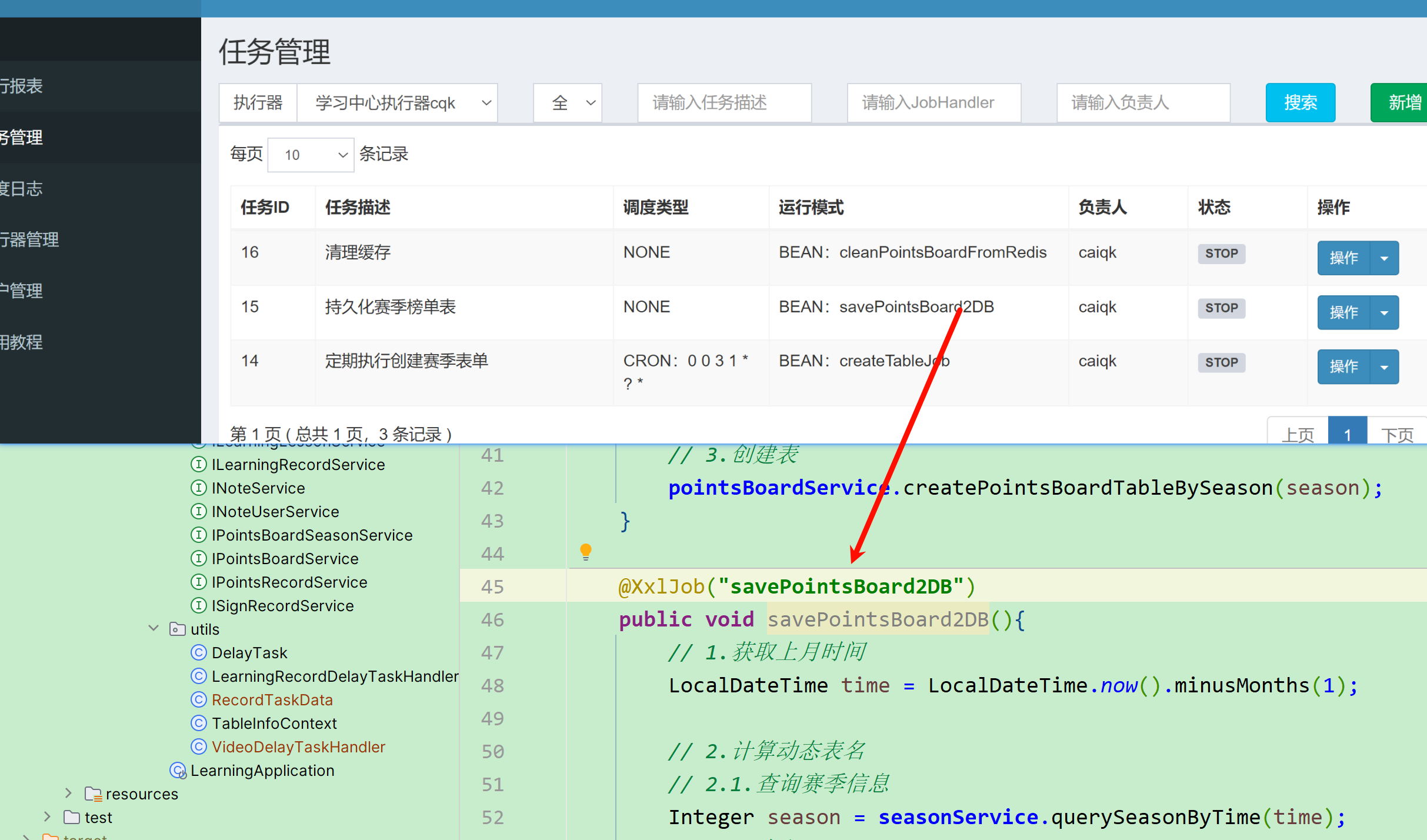
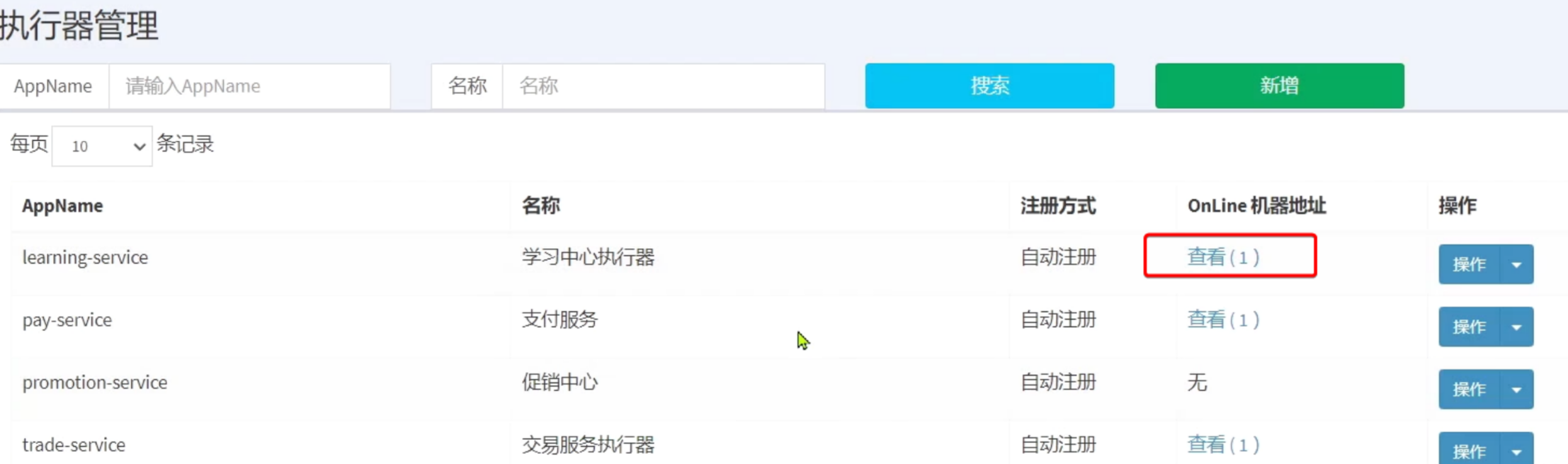
在弹出的窗口中填写信息:
等待一段时间,会发现learning-service已经成功注册了
配置任务调度
现在,执行器已经成功注册,任务也已经注册到调度中心。接下来,我们就可以来做任务调度了,也就是:
- 分配任务什么时候执行
- 如果有多个执行器,应该由哪个执行器执行(路由策略)
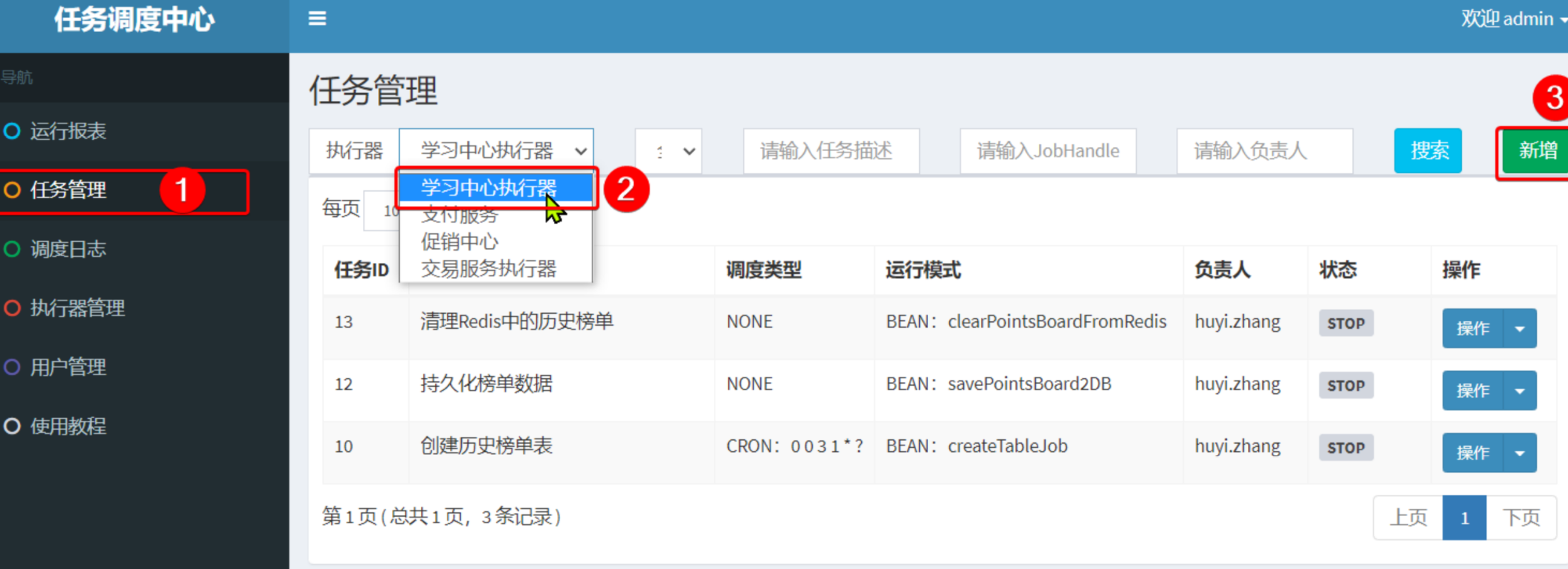
我们进入任务管理菜单,选中学习中心执行器,然后新增任务:
在弹出表单中,填写任务调度信息:
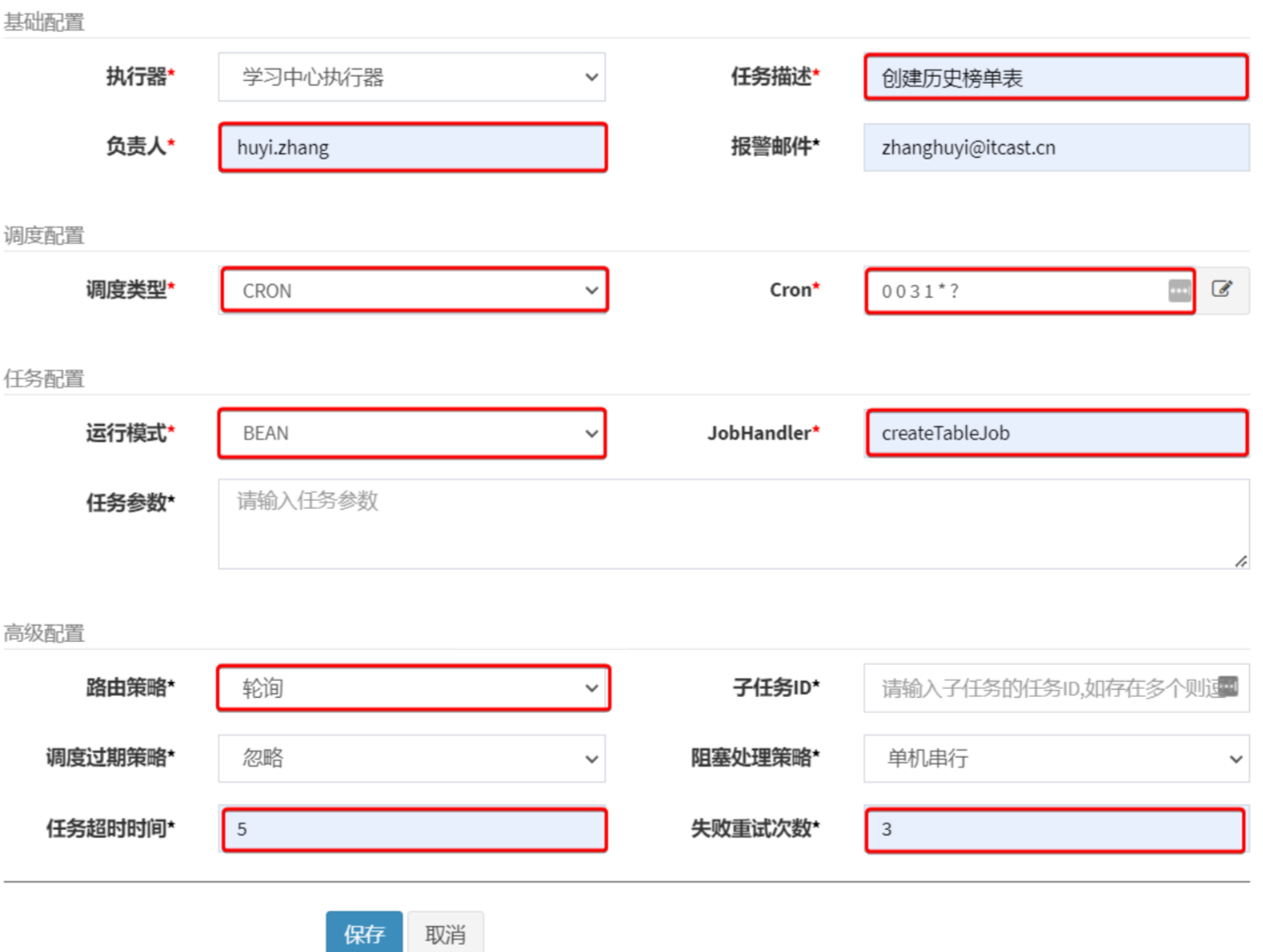
其中比较关键的几个配置:
- 调度配置:也就是什么时候执行,一般选择cron表达式
- 任务配置:采用BEAN模式,指定JobHandler,这里指定的就是在项目中
@XxlJob注解中的任务名称 - 路由策略:就是指如果有多个任务执行器,该由谁执行?这里支持的策略非常多:
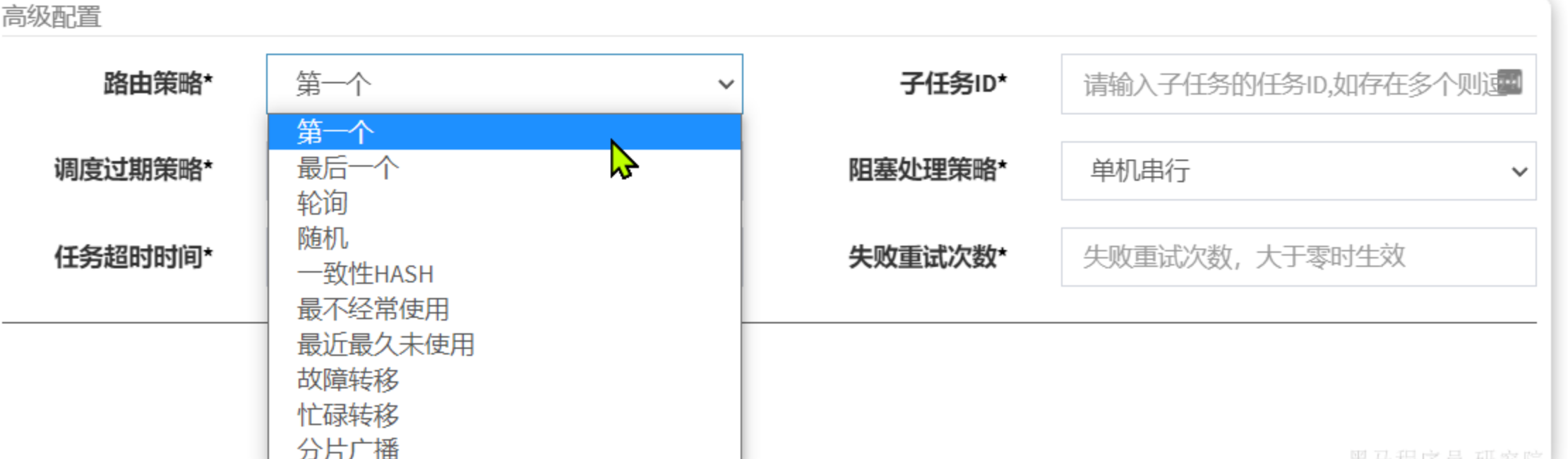
路由策略说明:
- FIRST(第一个):固定选择第一个执行器;
- LAST(最后一个):固定选择最后一个执行器;
- ROUND(轮询):在线的执行器按照轮询策略选择一个执行
- RANDOM(随机):随机选择在线的执行器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台执行器,且所有任务均匀散列在不同执行器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的执行器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久未使用的执行器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的执行器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的执行器选定为目标执行器并发起调度;
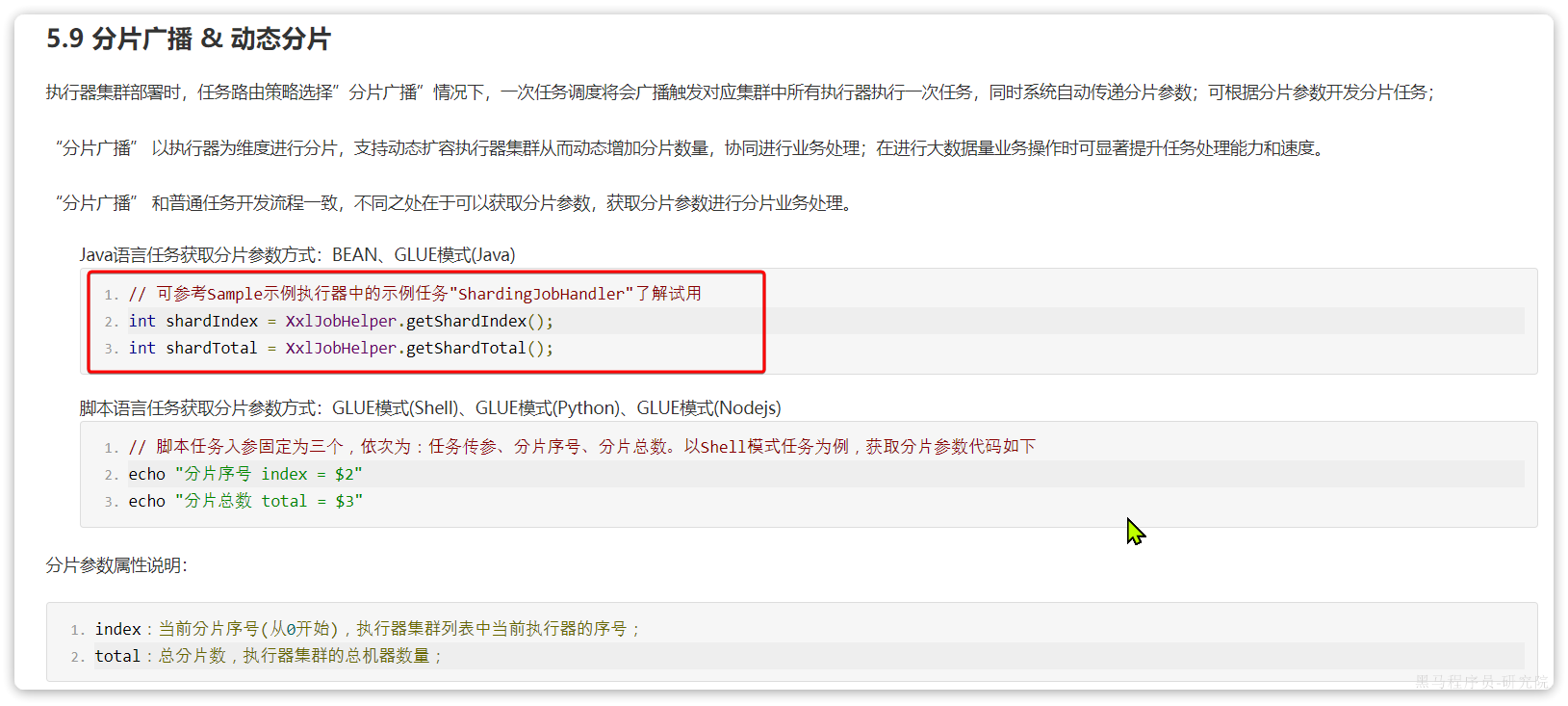
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务
XXL-JOB任务分片
刚才定义的定时持久化任务,通过while死循环,不停的查询数据,直到把所有数据都持久化为止。这样如果数据量达到数百万,交给一个任务执行器来处理会耗费非常多时间。 因此,将来肯定会将学习服务多实例部署,这样就会有多个执行器并行执行。但是,如果交给多个任务执行器,大家执行相同代码,都从第1页逐页处理数据,又会出现重复处理的情况。
怎么办? 这就要用到 任务分片 的方案了。
怎样才能确保任务不重复呢?我们可以参考扑克牌发牌的原理:
- 逐一给每个人发牌
- 发完一圈后,再回头给第一个人发
- 重复上述动作,直到牌发完为止
与此类似,比如我们启动了3个服务实例,就有3个执行器。我们可以把执行器当做打牌的人,然后把每一页数据作为一张牌:
- 把每页数据逐一分发给每个执行器,
- 发完一圈后,再回到第一个执行器。
- 直到所有页数据都发放完毕。 那么数据分发的过程如图:
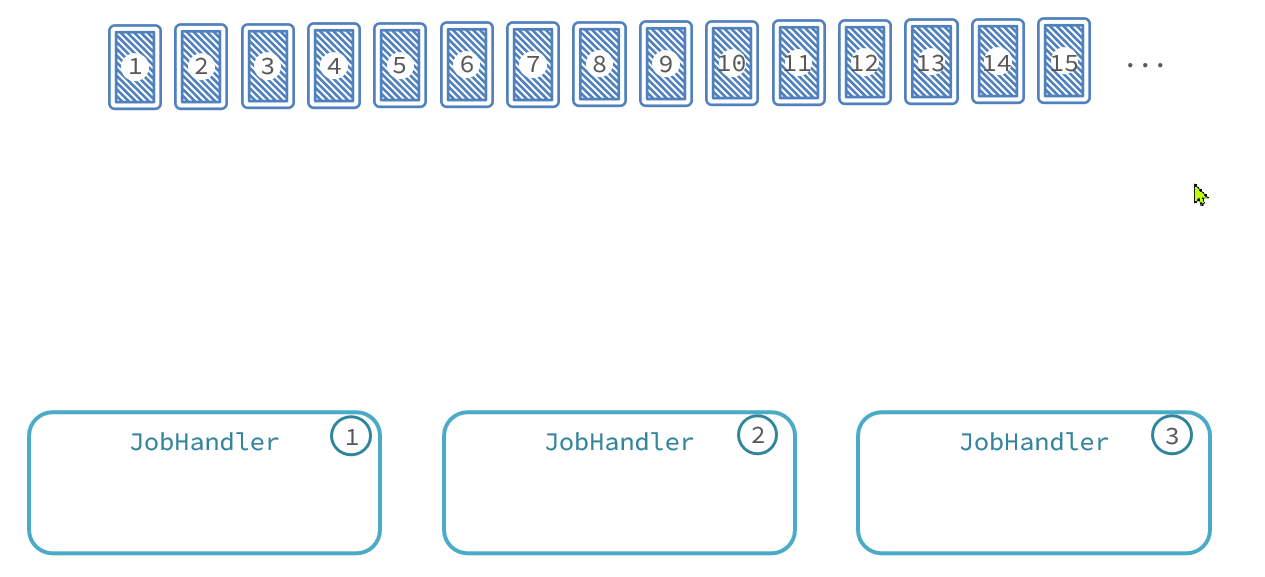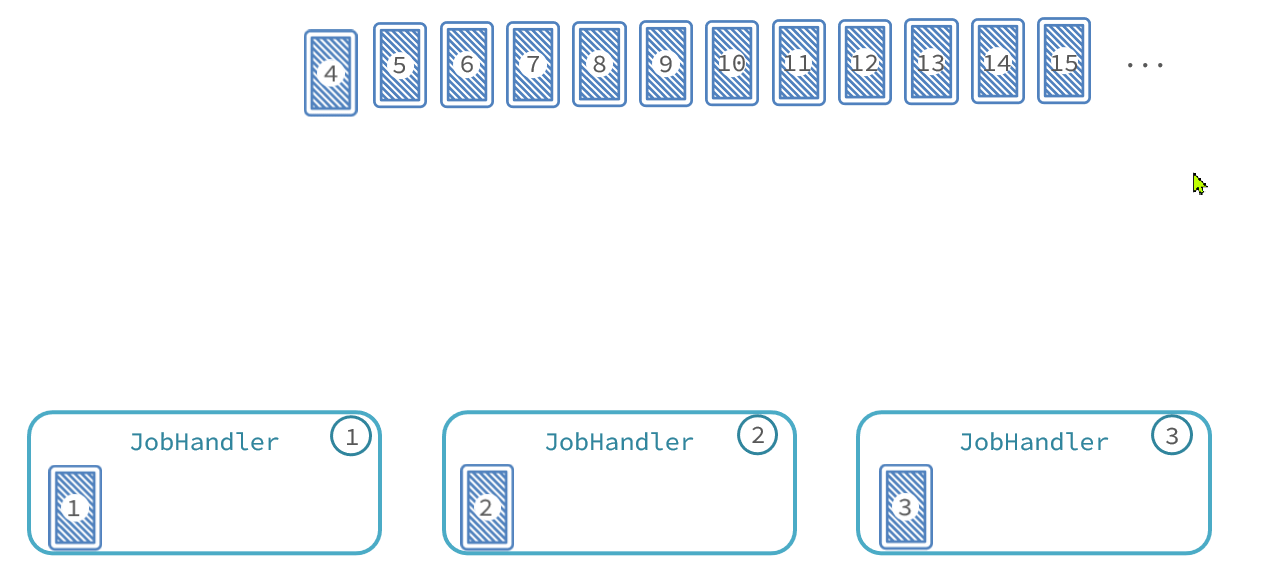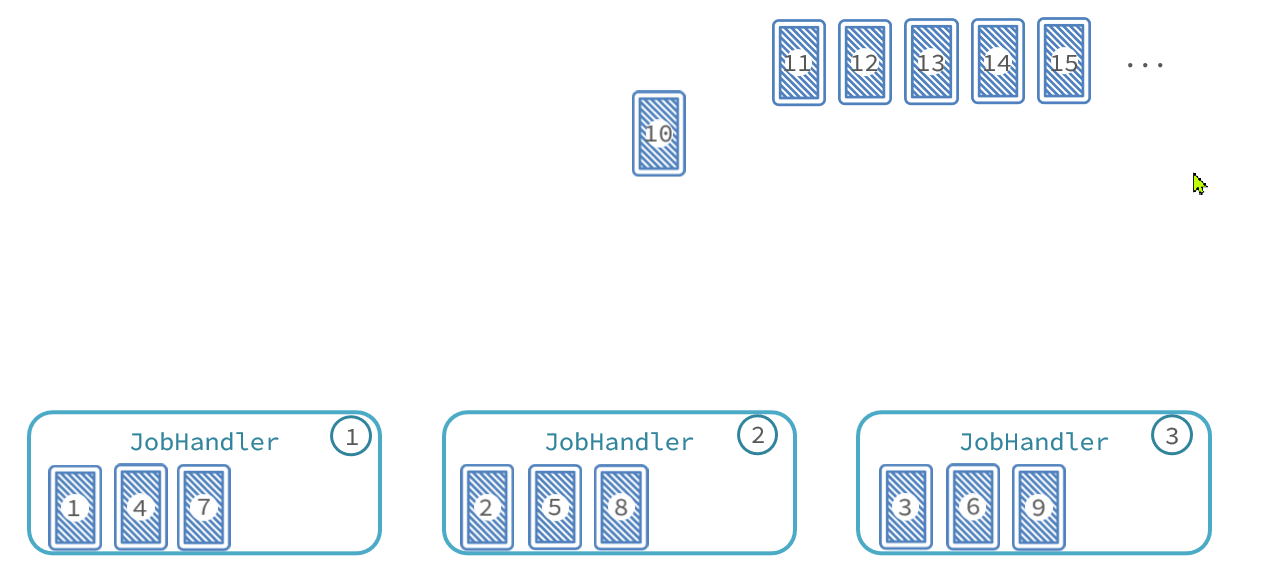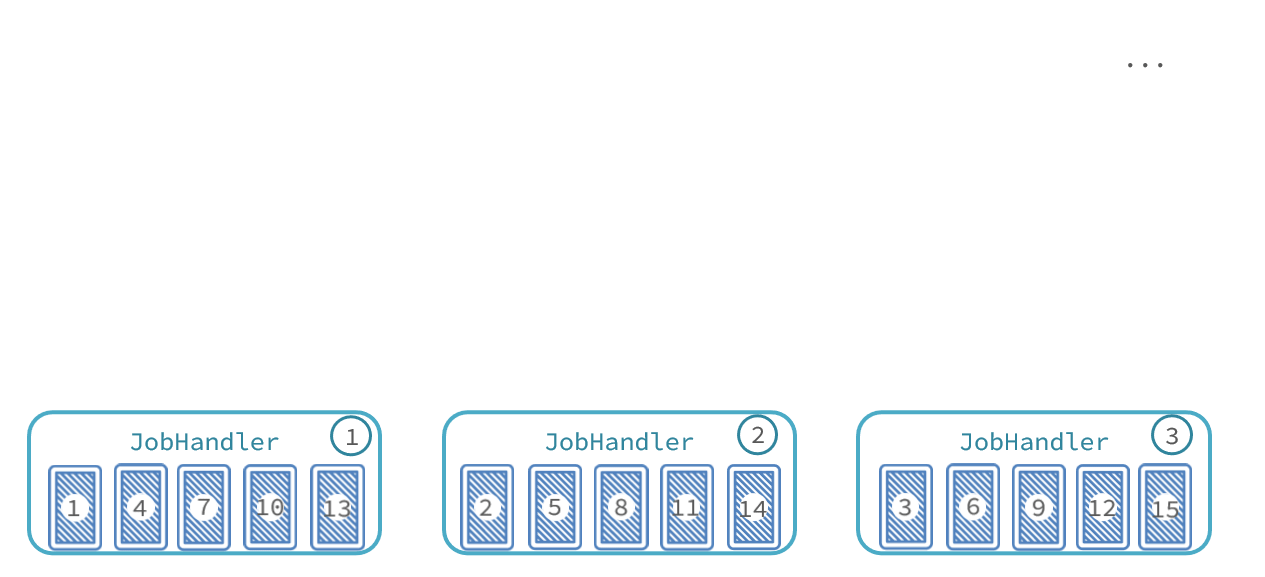
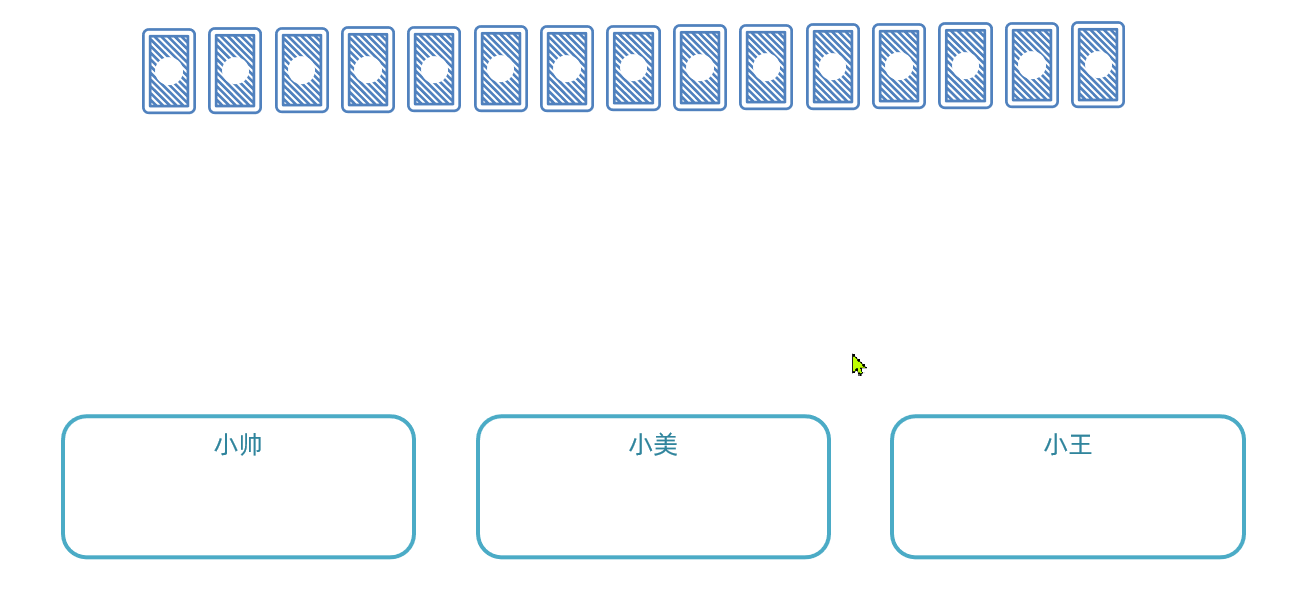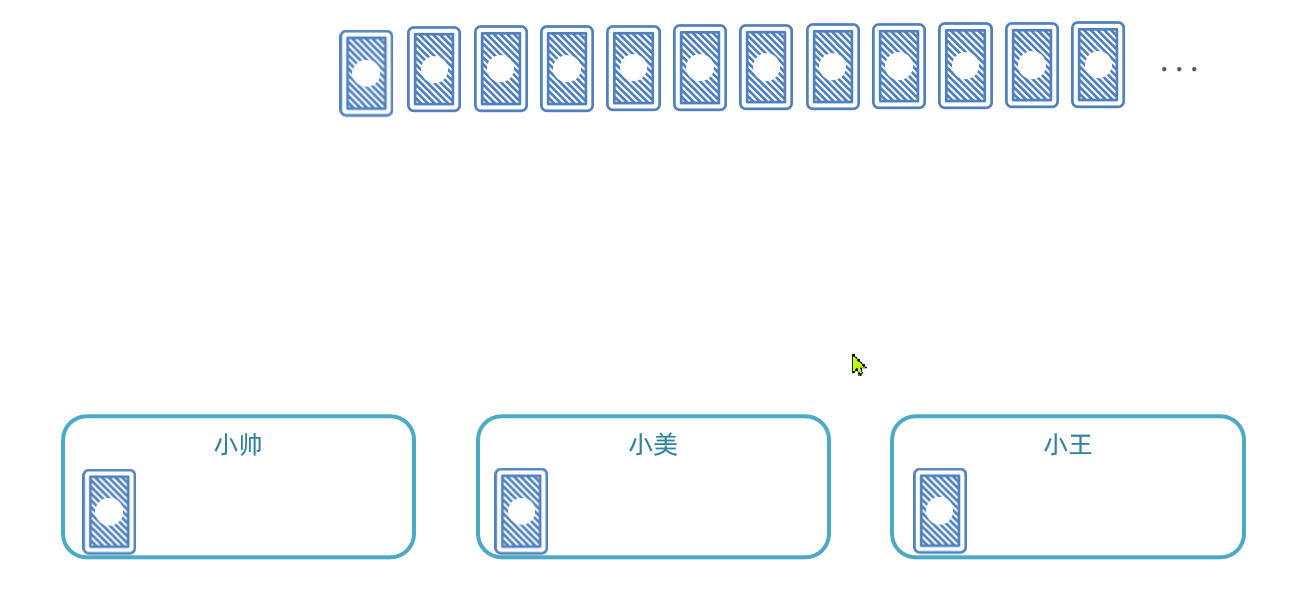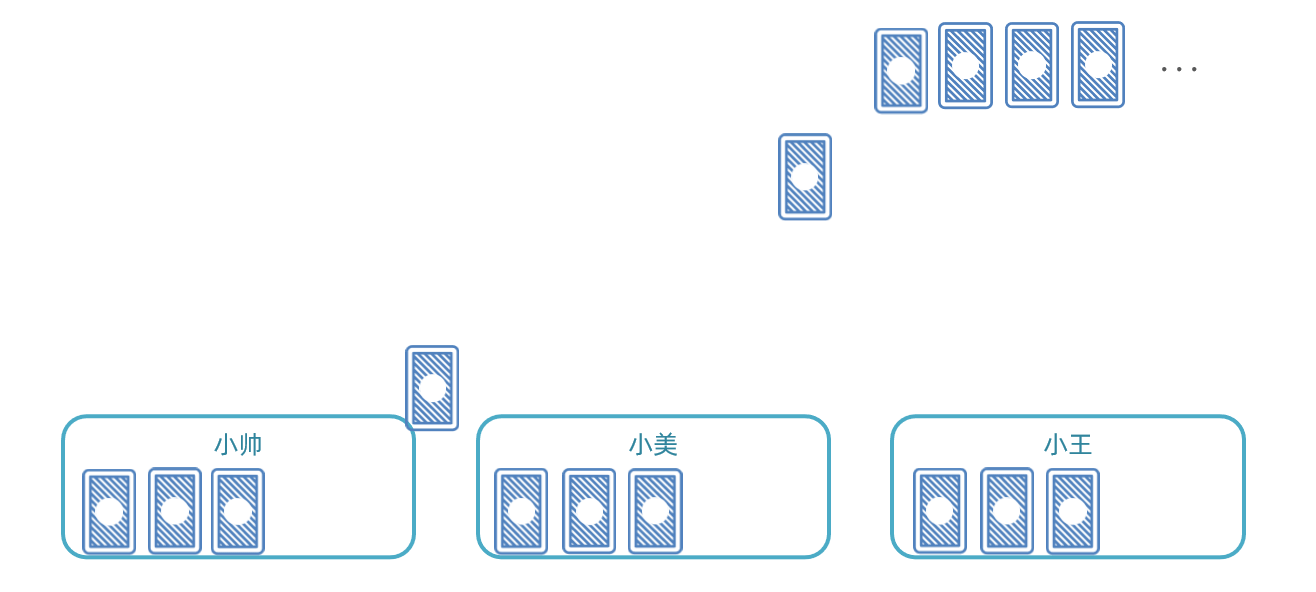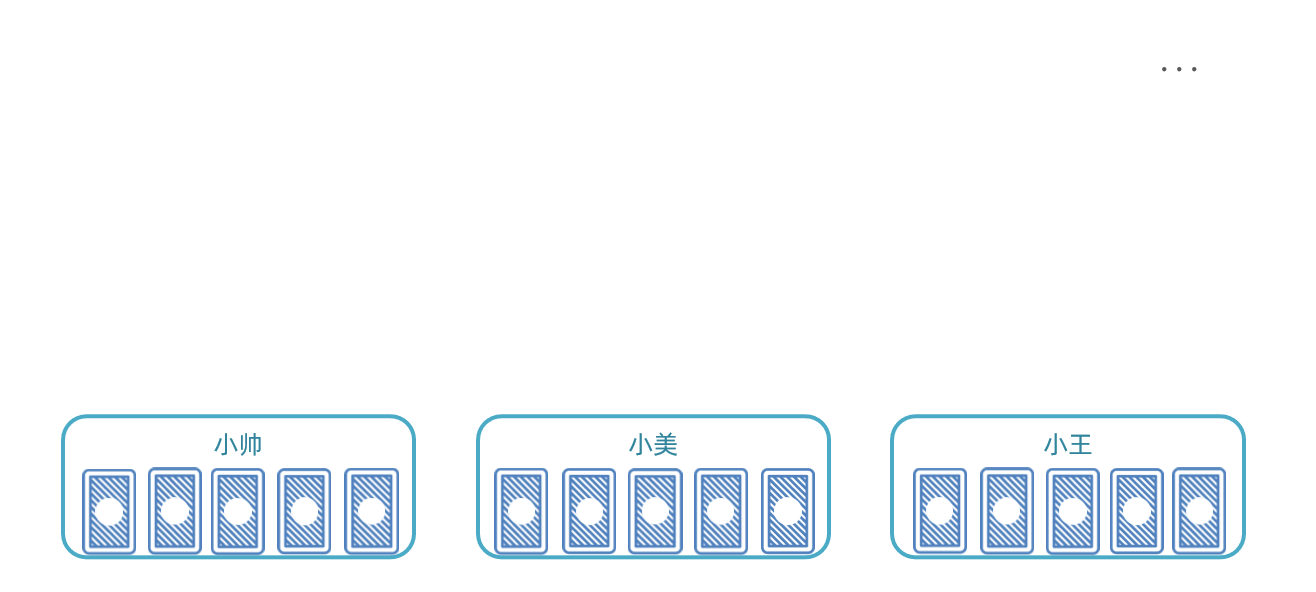
最终,每个执行器处理的数据页情况:
- 执行器1:处理第1、4、7、10、13、...页数据
- 执行器2:处理第2、5、8、11、14、...页数据
- 执行器3:处理第3、6、9、12、15、...页数据
要想知道每一个执行器执行哪些页数据,只要弄清楚两个关键参数即可:
- 起始页码:pageNo
- 下一页的跨度:step
而这两个参数是有规律的:
- 起始页码:执行器编号是多少,起始页码就是多少
- 页跨度:执行器有几个,跨度就是多少。也就是说你要 跳过别人读取过的页码
因此,现在的关键就是获取两个数据:
- 执行器编号
- 执行器数量
这两个参数XXL-JOB作为任务调度中心,肯定是知道的,而且也提供了API帮助我们获取:
以上就是我在项目中的Xxl-job使用,关于更多原理后续会继续添加!






评论( 0 )